Adelman, C. (1993). Kurt Lewin and the origins of action research. Educational Action Research, 1, 7-24.
Adler, E. S., & Clark, R. (2008). How it’s done: An invitation to social research (3rd ed.). Belmont, CA: Thomson Wadsworth
Agar, M., & MacDonald, J. (1995). Focus groups and ethnography. Human Organization, 54,78–86
Ainsworth, M., Blehar, M., Waters, E., & Wall, S. (1978). Patterns of attachment: A psychological study of the Strange Situation. Hillsdale, NJ: Erlbaum.
Alexander, B. (2010). Addiction: The view from rat park. Retrieved from: http://www.brucekalexander.com/articles-speeches/rat-park/148-addiction-the-view-from-rat-park
Allen, K. R., Kaestle, C. E., & Goldberg, A. E. (2011). More than just a punctuation mark: How boys and young men learn about menstruation. Journal of Family Issues, 32, 129–156.
American Sociological Association. (2011). Study: Negative classroom environment adversely affects children’s mental health. Retrieved from: https://www.sciencedaily.com/releases/2011/03/110309073717.htm
Arnett, J. J. (2008). The neglected 95%: Why American psychology needs to become less American. American Psychologist, 63, 602–614.
Arnold, D. S., O’Leary, S. G., Wolff, L. S., & Acker, M. M. (1993). The parenting scale: A measure of dysfunctional parenting in discipline situations. American Psychological Association, 5, 137–144
Babbie, E. (2010). The practice of social research (12th ed.). Belmont, CA: Wadsworth
Baicker, K., Taubman, S. L., Allen, H. L., Bernstein, M., Gruber, J. H., Newhouse, J. P., … & Finkelstein, A. N. (2013). The Oregon experiment—effects of Medicaid on clinical outcomes. New England Journal of Medicine, 368, 1713-1722
Baiden, P., Mengo, C., Boateng, G. O., & Small, E. (2018). Investigating the association between age at first alcohol use and suicidal ideation among high school students: Evidence from the youth risk behavior surveillance system. Journal of Affective Disorders, 242(2019), 60-67. doi: 10.1016/j.jad.2018.08.078
Baiden, P., Stewart, S. L., & Fallon, B. (2017). The role of adverse childhood experiences as determinants of non-suicidal self-injury among children and adolescents referred to community and inpatient mental health settings. Child Abuse & Neglect, 69, 163-176. doi: 10.1016/j.chiabu.2017.04.011
Bateman, P. J., Pike, J. C., & Butler, B. S. (2011). To disclose or not: Publicness in social networking sites. Information Technology & People, 24, 78–100.
Begley, S. (2010). What’s really human? The trouble with student guinea pigs. Newsweek. Retrieved from http://www.newsweek.com/2010/07/23/what-s-really- human.html
Belkin, L. (2003, October 26). The opt-out revolution. New York Times. Retrieved from https://www.nytimes.com/2003/10/26/magazine/the-opt-out-revolution.html
Berger, P. L., & Luckman, T. (1966). The social construction of reality: A treatise in the sociology of knowledge. New York, NY: Doubleday.
Berger, P. L. (1990). Nazi science: The Dachau hypothermia experiments. New England Journal of Medicine, 322, 1435–1440.
Berk, R., Campbell, A., Klap, R., & Western, B. (1992). The deterrent effect of arrest in incidents of domestic violence: A Bayesian analysis of four field experiments. American Sociological Review, 57, 698–708.
Berzins, M. (2009). Spams, scams, and shams: Content analysis of unsolicited email. International Journal of Technology, Knowledge, and Society, 5, 143–154
Best, S., & Kellner, D. (1991). Postmodern theory: Critical interrogations. New York, NY: Guilford.
Bhattacherjee, A. (2012). Social science research: Principles, methods, and practices. Textbook Collection. Retrieved from http://scholarcommons.usf.edu/oa_textbooks/3
Bode, K. (2017, January 26). One more time with feeling: ‘Anonymized’ user data not really anonymous. Techdirt. Retrieved from: https://www.techdirt.com/articles/20170123/08125136548/one-more-time-with-feeling-anonymized-user-data-not-really-anonymous.shtml
Bowlby, J. (1969). Attachment and loss: Volume 1. New York, NY: Basic Books.
Borzekowski, D. L. G., Schenk, S., Wilson, J. L., & Peebles, R. (2010). e-Ana and e-Mia: A content analysis of pro-eating disorder Web sites. American Journal of Public Health, 100, 1526–1534
Broderick, C.B. (1971). Beyond the five conceptual frameworks: A decade of development in family theory. Journal of Marriage and Family, 33(1), 139-159.
Bronfenbrenner, U. (1986). Ecology of the family as a context for human development: Research perspectives. Developmental Psychology, 22, 723-742.
Burnett, D. (2012). Inscribing knowledge: Writing research in social work. In W. Green & B. L. Simon (Eds.), The Columbia guide to social work writing (pp. 65-82). New York, NY: Columbia University Press.
Burns, G. L., & Patterson, D. R. (1990). Conduct problem behaviors in a stratified random sample of children and adolescents: New standardization data on Eyberg Child Behavior Inventory. Psychological Assessments, 2, 391–397
Buysse, J. A. M., & Embser-Herbert, M. S. (2004). Constructions of gender in sport: An analysis of intercollegiate media guide cover photographs. Gender & Society, 18, 66–81
Calhoun, C., Gerteis, J., Moody, J., Pfaff, S., & Virk, I. (Eds.). (2007). Classical sociological theory (2nd ed.). Malden, MA: Blackwell.
Campbell, D., & Stanley, J. (1963). Experimental and quasi-experimental designs for research. Chicago, IL: Rand McNally
Carroll, J. (2005). Who supports marijuana legalization? Retrieved from http://www.gallup.com/poll/19561/who-supports-marijuana-legalization.aspx
Charmaz, K. (2006). Constructing grounded theory: A practical guide through qualitative analysis. Thousand Oaks, CA: Sage
Cheung, J. C. S. (2016). Researching practice wisdom in social work. Journal of Social Intervention: Theory and Practice, 25(3), 24-38
Curtin, R., Presser, S., & Singer, E. (2000). The effects of response rate changes on the index of consumer sentiment. Public Opinion Quarterly, 64, 413–428
Davis, M., Johnson, M., Bowland, S. (In Draft) “I hate it…but it’s real”: Black Clergy Perspectives on Intimate Partner Violence related Religious/Spiritual Abuse
Davis, M., Dahm, C., Jonson-Reid, M., Stoops, C., Sabri, B. (Revisions Submitted-Awaiting Final Decision). “The Men’s Group” at St. Pius V: A Case Study of a Parish-Based Voluntary Partner Abuse Intervention Program.
de Montjoy, Y. A., Radaelli, L., & Singh, V. K. (2015). Unique in the shopping mall: On the reidentifiability of credit card metadata. Science, 347(6221), 536-539
DeCoster, S., Estes, S. B., & Mueller, C. W. (1999). Routine activities and sexual harassment in the workplace. Work and Occupations, 26, 21–49.
Delgado, R., & Stefancic, J. (2001). Critical race theory: An introduction. New York: New York University Press.
Devault, M. (1990). Talking and listening from women’s standpoint: Feminist strategies for interviewing and analysis. Social Problems, 37, 96–116
Dillman, D. A. (2000). Mail and Internet surveys: The tailored design method (2nd ed.). New York, NY: Wiley
Downs, E., & Smith, S. L. (2010). Keeping abreast of hypersexuality: A video game character content analysis. Sex Roles, 62, 721–733
Dubois, B. L., & Miley, K. K. (2005). Social work: An empowering profession, 5th ed. Boston, MA: Pearson.
Elliott, W., Jung, H., Kim, K., & Chowa, G. (2010). A multi-group structural equation model (SEM) examining asset holding effects on educational attainment by race and gender. Journal of Children & Poverty, 16, 91–121.
Ellwood, D., & Kane, T. (2000). Who gets a college education? Family background and growing gaps in enrollment. Securing the Future: Investing in Children from Birth to College.
Engel, R. J. & Schutt, R. K. (2016). The practice of research in social work (4th ed.). Washington, DC: SAGE Publishing
Esterberg, K. G. (2002). Qualitative methods in social research. Boston, MA: McGraw-Hill.
Faden, R. R., & Beauchamp, T. L. (1986). A history and theory of informed consent. Oxford, UK: Oxford University Press.
Faris, R., & Felmlee, D. (2011). Status struggles: Network centrality and gender segregation in same- and cross-gender aggression. American Sociological Review, 76, 48–73.
Faulkner, S. S. & Faulkner, C. A. (2016). Research methods for social workers: A practice-based approach. New York, NY: Oxford University Press.
Ferguson, K. M., Kim, M. A., & McCoy, S. (2011). Enhancing empowerment and leadership among homeless youth in agency and community settings: A grounded theory approach. Child and Adolescent Social Work Journal, 28, 1–22.
Frankfort-Nachmias, C. & Leon-Guerrero, A. (2011). Social statistics for a diverse society. Washington, DC: Pine Forge Press.
Fraser, N. (1989). Unruly practices: Power, discourse, and gender in contemporary social theory. Minneapolis, MN: University of Minnesota Press.
Gallagher, J. R., & Nordberg, A. (2016). Comparing and contrasting White and African American participants’ lived experiences in drug court. Journal of Ethnicity in Criminal Justice, 14, 100-119. doi: 10.1080/15377938.2015.1117999
Giorgi, A. and Giorgi, B. (2003). Phenomenology. In J. A. Smith (Ed.) Qualitative Psychology: A Practical Guide to Research Methods. London: Sage Publications.
Glaser, B. G., & Strauss, A. L. (1967). The discovery of grounded theory: Strategies for qualitative research. Chicago, IL: Aldine
Go, A. (2008). Two students kicked off semester at sea for plagiarism. U.S. News & World Report. Retrieved from http://www.usnews.com/education/blogs/paper-trail/2008/08/14/two-students-kicked-off-semester-at-sea-for-plagiarism
Goolsby, A. (2007). U.S. immigration policy in the regulatory era: Meaning and morality in state discourses of citizenship (Unpublished master’s thesis). Department of Sociology, University of Minnesota, Minneapolis, MN
Graaf, G. and Snowden, L. (2019). State approaches to funding home and community-based mental health care for non-Medicaid youth: Alternatives to Medicaid waivers. Administration and Policy in Mental Health and Mental Health Services Research. https://doi.org/10.1007/s10488-019-00933-2
Greenberg, J., & Hier, S. (2009). CCTV surveillance and the poverty of media discourse: A content analysis of Canadian newspaper coverage. Canadian Journal of Communication, 34, 461–486
Greene, V. W. (1992). Can scientists use information derived from the concentration camps? Ancient answers to new questions. In A. L. Caplan (Ed.), When medicine went mad: Bioethics and the Holocaust (p. 169–170). Totowa, NJ: Humana Press.
Guba, E. G. (1990). The paradigm dialog. Newbury Park, CA: Sage Publications
Healy, K. (2001). Participatory action research and social work: A critical appraisal. International Social Work, 44, 93-105
Heckathorn, D. D. (2012). Snowball versus respondent-driven sampling. Sociological Methodology, 41(1), 355-366. doi: 10.1111/j.1467-9531.2011.01244.x
Henrich, J., Heine, S. J., & Norenzayan, A. (2010). The weirdest people in the world? Behavioral and Brain Sciences, 33, 61–135
Hesse-Biber, S. N., & Leavy, P. L. (Eds.). (2007). Feminist research practice: A primer. Thousand Oaks, CA: Sage
Hoefer, R., Black, B., & Ricard, M. (2015). The impact of state policy on teen dating violence prevalence. Journal of Adolescence, 44, 88-96. doi: 10.1016/j.adolescence.2015.07.006
Hoefer, R. & Bryant, D. (2017). A quantitative evaluation of the Multi-Disciplinary Approach to Prevention Services (MAPS) program to protect children and strengthen families, Journal of Social Service Research, 43, 459-469, doi: 10.1080/01488376.2017.1295009
Hoefer, R., & Silva, S. M. (2010). Assessing and augmenting administration skills in nonprofits: An exploratory mixed methods study. Human Service Organizations: Management, Leadership & Governance, 38, 246-257. doi: 10.1080/23303131.2014.892049
Hollander, J. A. (2004). The social context of focus groups. Journal of Contemporary Ethnography, 33, 602–637.
Holt, J. L., & Gillespie, W. (2008). Intergenerational transmission of violence, threatened egoism, and reciprocity: A test of multiple psychosocial factors affecting intimate partner violence. American Journal of Criminal Justice, 33, 252–266.
Hopper, J. (2012, February 15). Rules of thumb for survey length. [blog post]. Versta Research. Retrieved from https://verstaresearch.com/blog/rules-of-thumb-for-survey-length/
Houle, J. (2008). Elliott Smith’s self-referential pronouns by album/year. Prepared for teaching SOC 207, Research Methods, at Pennsylvania State University, Department of Sociology
Huff, D. & Geis, I. (1993). How to lie with statistics. New York, NY: W. W. Norton & Co.
Hughes, M. E., Waite, L. J., Hawkley, L. C., & Cacioppo, J. T. (2004). A short scale for measuring loneliness in large surveys: Results from two population-based studies. Research on Aging, 26, 655-672. doi: 10.1177/0164027504268574
Humphreys, L. (1970). Tearoom trade: Impersonal sex in public places. London, UK: Duckworth.
Humphreys, L. (2008). Tearoom trade: Impersonal sex in public places, enlarged edition with a retrospect on ethical issues. New Brunswick, NJ: Aldine Transaction.
Jakobsson, S., Horvath, G., & Ahlberg, K. (2005). A grounded theory exploration of the first visit to a cancer clinic—strategies for achieving acceptance. European Journal of Oncology Nursing, 9(3), 248-257.
James, D., Schumm, W., Kennedy, C., Grigsby, C., & Shectman, K. (1985). Characteristics of the Kansas Parental Satisfaction Scale among two samples of married parents. Psychological Reports, 57(1), 163–169
Jaschik, S. (2009, December 4). Protecting his sources. Inside Higher Ed. Retrieved from: http://www.insidehighered.com/news/2009/12/04/demuth
Jenkins, P. J., & Kroll-Smith, S. (Eds.). (1996). Witnessing for sociology: Sociologists in court. Westport, CT: Praeger.
Johnson, P. S., & Johnson, M. W. (2014). Investigation of “bath salts” use patterns within an online sample of users in the United States. Journal of Psychoactive Drugs, 46(5), 369-378
Kaplan, A. (1964). The conduct of inquiry: Methodology for behavioral science. San Francisco, CA: Chandler Publishing Company.
Keeter, S., Dimock, M., & Christian, L. (2008). Calling cell phones in ’08 pre-election polls. The Pew Research Center for the People and the Press. Retrieved from https://assets.pewresearch.org/wp-content/uploads/sites/5/legacy-pdf/cell-phone-commentary.pdf
Keeter, S., Kennedy, C., Dimock, M., Best, J., & Craighill, P. (2006). Gauging the impact of growing nonresponse on estimates from a national RDD telephone survey. Public Opinion Quarterly, 70, 759–779;
Kezdy, A., Martos, T., Boland, V., & Horvath-Szabo, K. (2011). Religious doubts and mental health in adolescence and young adulthood: The association with religious attitudes. Journal of Adolescence, 34, 39–47
Kimmel, M. (2000). The gendered society. New York, NY: Oxford University Press; Kimmel, M. (2008). Masculinity. In W. A. Darity Jr. (Ed.), International encyclopedia of the social sciences (2nd ed., Vol. 5, p. 1–5). Detroit, MI: Macmillan Reference USA
Kimmel, M. (2008). Guyland: The perilous world where boys become men. New York, NY: Harper Collins
Kimmel, M. (2008). Masculinity. In W. A. Darity Jr. (Ed.), International encyclopedia of the social sciences (2nd ed., Vol. 5, p. 1–5). Detroit, MI: Macmillan Reference USA
Kimmel, M. & Aronson, A. B. (2004). Men and masculinities: A-J. Denver, CO: ABL-CLIO.
King, R. D., Messner, S. F., & Baller, R. D. (2009). Contemporary hate crimes, law enforcement, and the legacy of racial violence. American Sociological Review, 74, 291–315.
Kogan, S. M., Wejnert, C., Chen, Y., Brody, G. H., & Slater, L. M. (2011). Respondent-driven sampling with hard-to-reach emerging adults: An introduction and case study with rural African Americans. Journal of Adolescent Research, 26, 30–60.
Krueger, R. A., & Casey, M. A. (2000). Focus groups: A practical guide for applied research (3rd ed.). Thousand Oaks, CA: Sage
Kuhn, T. (1962). The structure of scientific revolutions. Chicago, IL: University of Chicago Press.
LaBrenz, C. & Fong, R. (2016). Outcomes of family centered meetings for families referred to Child Protective Services. Children and Youth Services Review, 71, 93-102. doi: 10.1016/j.childyouth.2016.10.032
Langer, G. (2003). About response rates: Some unresolved questions. Public Perspective, May/June, 16–18. Retrieved from: https://www.aapor.org/AAPOR_Main/media/MainSiteFiles/Response_Rates_-_Langer.pdf
Lee, K. (2018). Older adults and volunteering: A comprehensive study on physical and psychological well-being and cognitive health (Doctoral dissertation). Proquest Dissertations Publishing. 11005225.
Lenza, M. (2004). Controversies surrounding Laud Humphreys’ tearoom trade: An unsettling example of politics and power in methodological critiques. International Journal of Sociology and Social Policy, 24, 20–31.
Liamputtong, P. (2011). Focus group methodology: Principles and practice. Washington, DC: Sage.
Lisk, J. (2011). Addiction to our electronic gadgets. Retrieved from: https://www.youtube.com/watch?v=9lVHZZG5qvw
Loewen, J. W. (2007). Lies my teacher told me: Everything your American history textbook got wrong. Grenwich, CT: Touchstone.
MacKinnon, C. 1979. Sexual harassment of working women: A case of sex discrimination. New Haven, CT: Yale University Press.
Maffly, B. (2011, August 19). “Pattern of plagiarism” costs University of Utah scholar his job. The Salt Lake Tribune. Retrieved from http://www.sltrib.com/sltrib/cougars/52378377-78/bakhtiari-university-panel-plagiarism.html.csp?page=1
Markham, A., & Buchanan, E. (2012). Ethical decision-making and internet research: Recommendations from the AoIR ethics working committee (version 2.0). Retrieved from http://www.aoir.org/reports/ethics.pdf
Markham, A., & Buchanan, E. (2017). Research ethics in context decision-making in digital research in M. T. Schäfer and K. van Es (Eds.), The Datafied Society (pp. 201-210). Amsterdam University Press. Retrieved from https://www.jstor.org/stable/j.ctt1v2xsqn.19
McCoy, S. K., & Major, B. (2003). Group identification moderates emotional response to perceived prejudice. Personality and Social Psychology Bulletin, 29, 1005–1017.
Merkle, D. M., & Edelman, M. (2002). Nonresponse in exit polls: A comprehensive analysis. In M. Groves, D. A. Dillman, J. L. Eltinge, & R. J. A. Little (Eds.), Survey nonresponse (pp. 243–258). New York, NY: John Wiley and Sons.
Messner, M. A. (2002). Taking the field: Women, men, and sports. Minneapolis: University of Minnesota Press.
Messner, M. A., Duncan, M. C., & Jensen, K. (1993). Separating the men from the girls: The gendered language of televised sports. Gender & Society, 7, 121–137
Milkie, M. A., & Warner, C. H. (2011). Classroom learning environments and the mental health of first grade children. Journal of Health and Social Behavior, 52, 4–22.
Milgram, S. (1974). Obedience to authority: An experimental view. New York, NY: Harper & Row.
Miyawaki, C. E., Mauldin, R. L., & Carman, C. R. (2019). Optometrists’ referrals to community-based exercise programs: Finding from a mixed-methods feasibility study. Journal of Aging and Physical Activity. doi: 10.1123/japa.2018-0442
Milkie, M. A., & Warner, C. H. (2011). Classroom learning environments and the mental health of first grade children. Journal of Health and Social Behavior, 52, 4–22.
Moe, K. (1984). Should the Nazi research data be cited? The Hastings Center Report, 14, 5–7.
Morgan, D. L. (1997). Focus groups as qualitative research (2nd ed.). Thousand Oaks, CA: Sage.
Morgan, P. A. (1999). Risking relationships: Understanding the litigation choices of sexually harassed women. The Law and Society Review, 33, 201–226.
Mortimer, J. T. (2003). Working and growing up in America. Cambridge, MA: Harvard University Press.
National Commission for the Protection of Human Subjects in Biomedical and Behavioral Research. (1979). The Belmont report: Ethical principles and guidelines for the protection of human subjects of research. Retrieved from https://www.hhs.gov/ohrp/regulations-and-policy/belmont-report/index.html
National Research Act of 1974, Pub. L. no. 93-348 Stat 88. (1974). The act can be read at https://history.nih.gov/research/downloads/PL93-348.pdf
Neuendorf, K. A., Gore, T. D., Dalessandro, A., Janstova, P., & Snyder-Suhy, S. (2010). Shaken and stirred: A content analysis of women’s portrayals in James Bond films. Sex Roles, 62, 747–761.
Neuman, W. L. (2003). Social research methods: Qualitative and quantitative approaches (5th ed.). Boston, MA: Pearson
Neuman, W. L. (2007). Basics of social research: Qualitative and quantitative approaches (2nd ed.). Boston, MA: Pearson
Nordberg, A., Crawford, M. R., & Praetorius, R. T. (2016). Exploring minority youths’ police encounters: A qualitative interpretive meta-synthesis. Child and Adolescent Social Work Journal, 33, 137-149. doi: 10.1007/s10560-015-0415-3
Oakley, A. (1981). Interviewing women: A contradiction in terms. In H. Roberts (Ed.), Doing feminist research (pp. 30–61). London, UK: Routledge & Kegan Paul
Ogden, R. (2008). Harm. In L. M. Given (Ed.), The SAGE encyclopedia of qualitative research methods (p. 379–380). Los Angeles, CA: Sage.
Open Science Collaboration. (2015). Estimating the reproducibility of psychological science. Science, 349(6251), aac4716.
Padgett, D. K. (2016). Qualitative methods in social work research (Vol. 36). Thousand Oaks, CA: Sage Publications.
Padilla-Medina, D., Rodríguez, E., & Vega, G. (2019). Gender Role Beliefs and Puerto Rican Adolescents intention to use abusive behaviors in romantic relationships: A consideration of developmental and gender variations. Manuscript under review
Padilla-Medina, D., Rodríguez, E., Vega, G., & Williams, J. (2019). Understanding the behavioral determinants Influencing Puerto Rican adolescents’ decision to engage in romantic relationship violence. Manuscript under review.
Parisi, M. (1989). Alien cartoon 6. Off the Mark. Retrieved from: http://www.offthemark.com/System/2006-05-30
Pate, A., & Hamilton, E. (1992). Formal and informal deterrents to domestic violence: The Dade county spouse assault experiment. American Sociological Review, 57, 691–697.
Percheski, C. (2008). Opting out? Cohort differences in professional women’s employment rates from 1960 to 2005. American Sociological Review, 73, 497–517
Petrie, B. F. (1996). Environment is not the most important variable in determining oral morphine consumption in Wistar rats. Psychological Reports, 78(2), 391-400
Pew Research (n.d.) Sampling. Retrieved from: http://www.pewresearch.org/methodology/u-s-survey-research/sampling/
Piercy, F. P., Franz, N., Donaldson, J. L., & Richard, R. F. (2011). Consistency and change in participatory action research: Reflections on a focus group study about how farmers learn. The Qualitative Report, 16, 820–829
Pozos, R. S. (1992). Scientific inquiry and ethics: The Dachau data. In A. L. Caplan (Ed.), When medicine went mad: Bioethics and the Holocaust (p. 104). Totowa, NJ: Humana Press.
Reason, P. (1994). Participation in human inquiry. London, UK: Sage
Reinharz, S. (1992). Feminist methods in social research. New York, NY: Oxford University Press
Reverby, S. M. (2009). Examining Tuskegee: The infamous syphilis study and its legacy. Chapel Hill, NC: University of North Carolina Press
Rodwell, M. K. (1998). Social work constructivist research. New York, NY: Garland Publishing
Rothman, D. J. (1987). Ethics and human experimentation. The New England Journal of Medicine, 317, 1195–1199.
Rubin, C. & Babbie, S. (2017). Research methods for social work (9th edition). Boston, MA: Cengage
Rubin, A., and Babbie, E. R. (2017). Research methods for social work (9th ed.). Belmont: Wadsworth.
Sadker, M., & Sadker, D. (1994). Failing at fairness: How America’s schools cheat girls. New York, NY: Maxwell Macmillan International.
Schaller, M. (1997). The psychological consequences of fame: Three tests of the self-consciousness hypothesis. Journal of Personality, 65, 291– 309
Shakur, S. (1993). Monster: The autobiography of an L.A. gang member. New York, NY: Atlantic Monthly Press.
Schriver, J. M. (2011). Human behavior and the social environment: Shifting paradigms in essential knowledge for social work practice (5th ed.) Boston, MA: Pearson.
Schutt, R. K. (2006). Investigating the social world: The process and practice of research. Thousand Oaks, CA: Pine Forge Press.
Sheikh, J. I., & Yesavage, J. A. (1986). 9/Geriatric Depression Scale (GDS): Recent evidence and development of a shorter version. Clinical Gerontologist, 5(1/2), 165-172. doi: 10.1300/J018v05n01_09
Sherman, L. W., & Berk, R. A. (1984). The specific deterrent effects of arrest for domestic assault. American Sociological Review, 49, 261–272.
Simons, D. A., & Wurtele, S. K. (2010). Relationships between parents’ use of corporal punishment and their children’s endorsement of spanking and hitting other children. Child Abuse & Neglect, 34, 639–646.
Slater, H. M., & Mitschke, D.B. (2015). Evaluation of the Crossroads Program in Arlington, TX: Findings from an Innovative Teen Pregnancy Prevention Program, Arlington, TX: University of Texas at Arlington.
Slater, A., & Tiggemann, M. (2010). “Uncool to do sport”: A focus group study of adolescent girls’ reasons for withdrawing from physical activity. Psychology of Sport and Exercise, 11, 619–626
Smith, L. T. (2013). Decolonizing methodologies: Research and indigenous peoples (2nd edition). London: Zed Books, Ltd.
Smith, T. W. (2009). Trends in willingness to vote for a black and woman for president, 1972–2008. GSS Social Change Report No. 55. Chicago, IL: National Opinion Research Center
Solinas, M., Thiriet, N., El Rawas, R., Lardeux, V., & Jaber, M. (2009). Environmental enrichment during early stages of life reduces the behavioral, neurochemical, and molecular effects of cocaine. Neuropsychopharmacology, 34, 1102
Stacey, J. (1988). Can there be a feminist ethnography? Women’s Studies International Forum, 11, 21–27
Stratmann, T. & Wille, D. (2016). Certificate-of-need laws and hospital quality. Mercatus Center at George Mason University, Arlington, VA. Retrieved from: https://www.mercatus.org/system/files/mercatus-stratmann-wille-con-hospital-quality-v1.pdf
Substance Abuse and Mental Health Services Administration (2007). Pathways’ housing first program. Retrieved from: https://pathwaystohousingpa.org/sites/pathwaystohousingpa.org/files/Pathways%20Housing%20First%20Evidence-based.pdf
Trucco, E.M. (2012). Contextual factors in substance use: How neighborhoods, parents, and peers impact substance use in an early adolescent sample. ProQuest Dissertation Publishing (3541306).
Uggen, C., & Blackstone, A. (2004). Sexual harassment as a gendered expression of power. American Sociological Review, 69, 64–92.
US Department of Health and Human Services. (1993). Institutional review board guidebook glossary. Retrieved from https://ori.hhs.gov/education/products/ucla/chapter2/page00b.html
US Department of Health and Human Services. (2009). Code of federal regulations (45 CFR 46).
Venkatesh, S. (2008). Gang leader for a day: A rogue sociologist takes to the streets. New York, NY: Penguin Group.
von Hoffman, N. (1970, January 30). Sociological snoopers. The Washington Post, p. B1.
Voth Schrag, R., Ravi, K., & Robinson, S. (2019). Understanding the needs of non-service seeking survivors. Austin, TX: Texas Council on Family Violence
Wal-Mart Stores, Inc. v. Dukes, 564 U.S. (2011)
Warwick, D. P. (1973). Tearoom trade: Means and ends in social research. Hastings Center Studies, 1, 39–49.
Warwick, D. P. (1982). Types of harm in social research. In T. L. Beauchamp, R. R. Faden, R. J. Wallace Jr., & L. Walters (Eds.), Ethical issues in social science research. Baltimore, MD: Johns Hopkins University Press
Weiner, M. (2010). Power, protest, and the public schools: Jewish and African American struggles in New York City. Piscataway, NJ: Rutgers University Press
Wilson, P. M., Petticrew, M., Calnan, M. W., & Natareth, I. (2010). Disseminating research findings: What should researchers do? A systematic scoping review of conceptual frameworks. Implementation Science, 5, 91.
Wong, W. (2007). The top 10 hand gestures you’d better get right. Retrieved from http://www.languagetrainers.co.uk/blog/2007/09/24/top-10-hand-gestures
Ylanne, V., & Williams, A. (2009). Positioning age: Focus group discussions about older people in TV advertising. International Journal of the Sociology of Language, 200, 171–187.






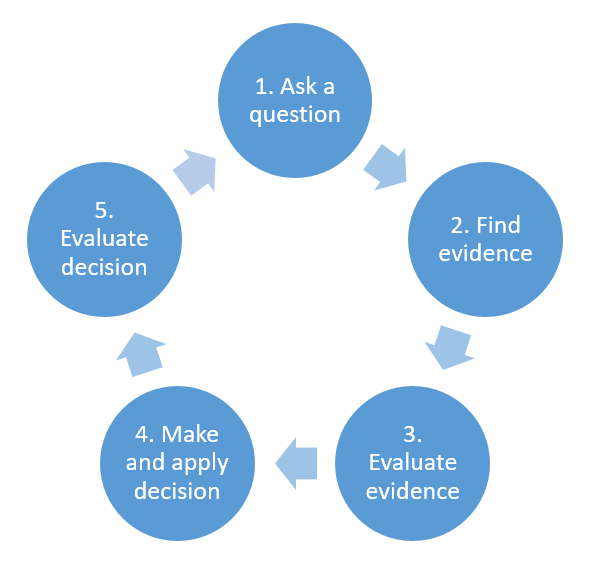





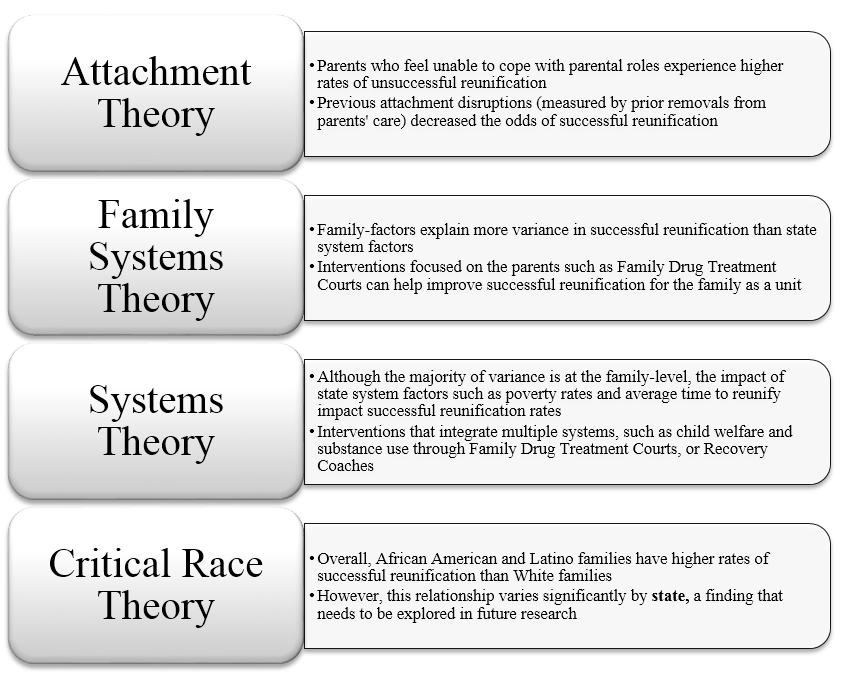


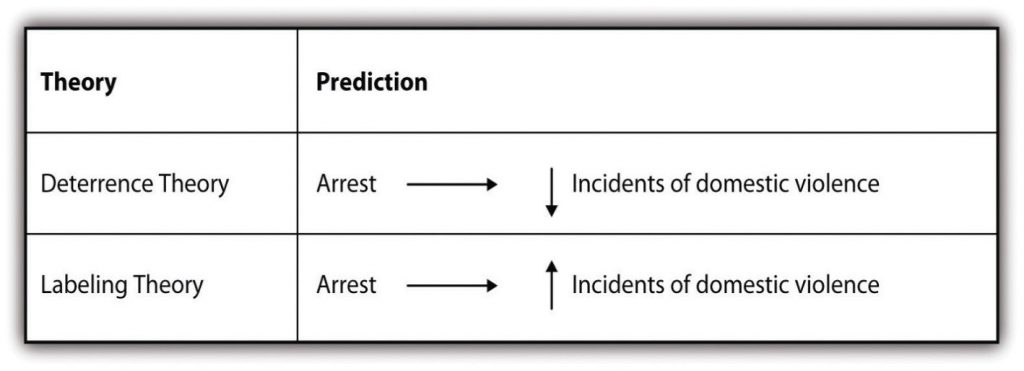
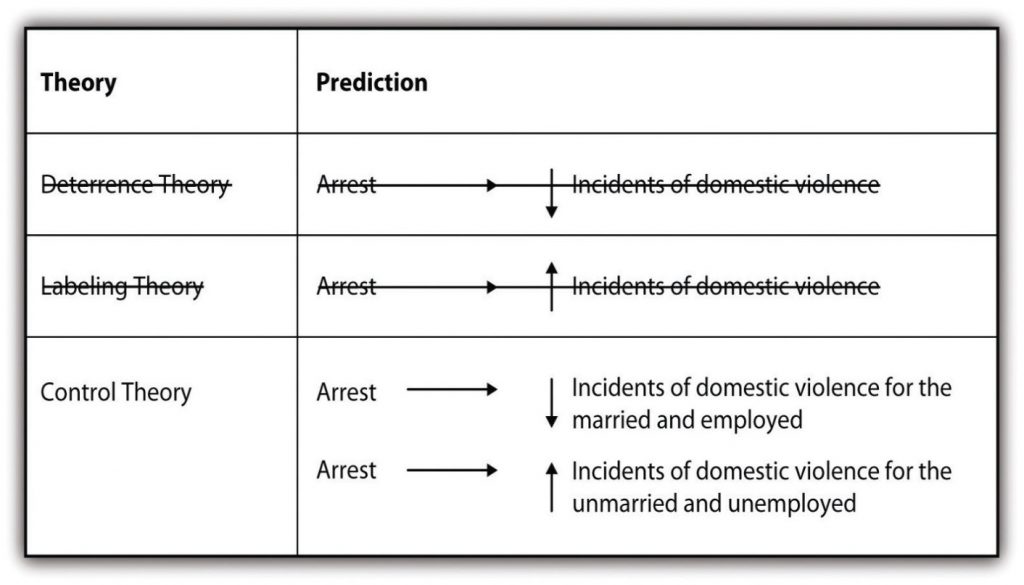





















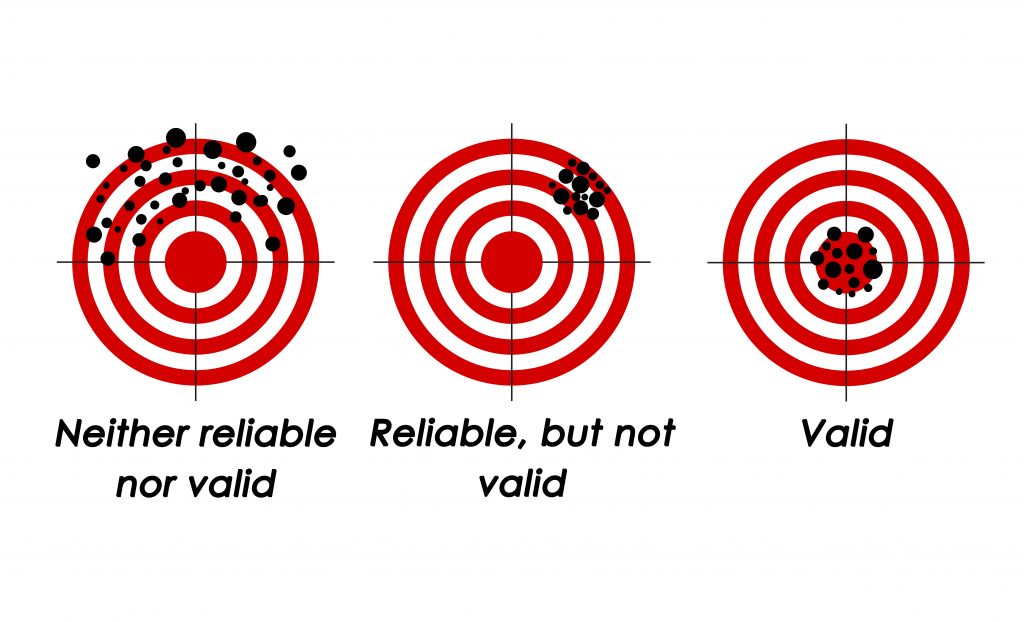




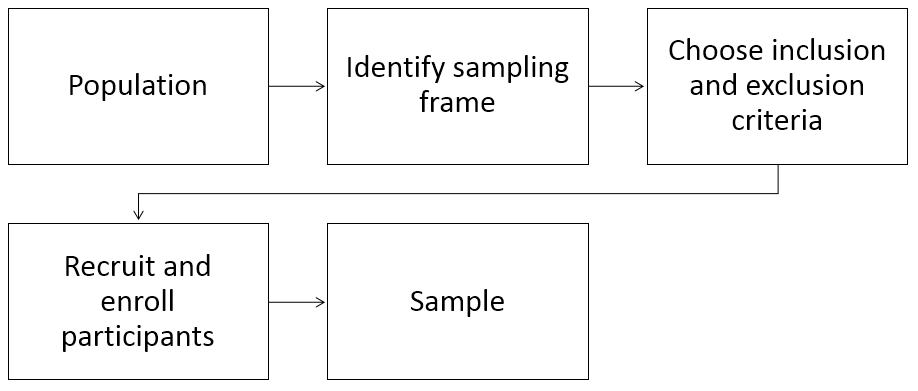
















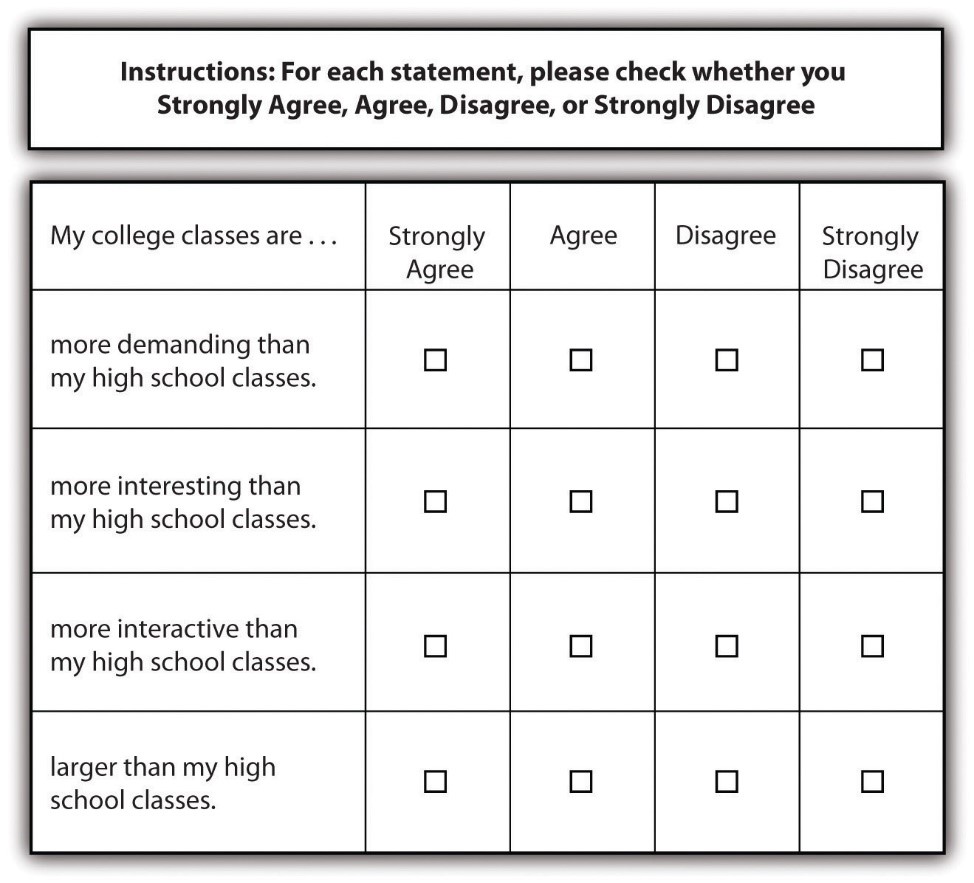


































{kind=link}
{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}