9 Introduction to Transportation Modeling: Travel Demand Modeling and Data Collection
Chapter Overview
Chapter 9 serves as an introduction to travel demand modeling, a crucial aspect of transportation planning and policy analysis. As explained in previous chapters, the spatial distribution of activities such as employment centers, residential areas, and transportation systems mutually influence each other. The utilization of travel demand forecasting techniques leads to dynamic processes in urban areas. A comprehensive grasp of travel demand modeling is imperative for individuals involved in transportation planning and implementation.
This chapter covers the fundamentals of the traditional four-step travel demand modeling approach. It delves into the necessary procedures for applying the model, including establishing goals and criteria, defining scenarios, developing alternatives, collecting data, and conducting forecasting and evaluation.
Following this chapter, each of the four steps will be discussed in detail in Chapters 10 through 13.
Learning Objectives
- Describe the need for travel demand modeling in urban transportation and relate it to the structure of the four-step model (FSM).
- Summarize each step of FSM and the prerequisites for each in terms of data requirement and model calibration.
- Summarize the available methods for each of the first three steps of FSM and compare their reliability.
- Identify assumptions and limitations of each of the four steps and ways to improve the model.
Introduction
Transportation planning and policy analysis heavily rely on travel demand modeling to assess different policy scenarios and inform decision-making processes. Throughout our discussion, we have primarily explored the connection between urban activities, represented as land uses, and travel demands, represented by improvements and interventions in transportation infrastructure. Figure 9.1 provides a humorous yet insightful depiction of the transportation modeling process. In preceding chapters, we have delved into the relationship between land use and transportation systems, with the houses and factories in the figure symbolizing two crucial inputs into the transportation model: households and jobs. The output of this model comprises transportation plans, encompassing infrastructure enhancements and programs. Chapter 9 delves into a specific model—travel demand modeling. For further insights into transportation planning and programming, readers are encouraged to consult the UTA OERtransport book, “Transportation Planning, Policies, and History.”
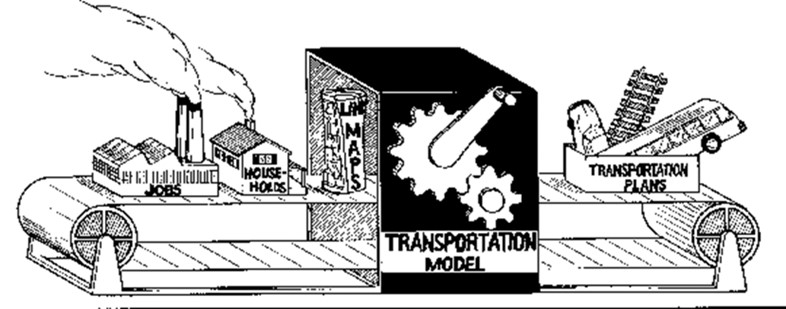
Travel demand models forecast how people will travel by processing thousands of individual travel decisions. These decisions are influenced by various factors, including living arrangements, the characteristics of the individual making the trip, available destination options, and choices regarding route and mode of transportation. Mathematical relationships are used to represent human behavior in these decisions based on existing data.
Through a sequential process, transportation modeling provides forecasts to address questions such as:
- What will the future of the area look like?
- What is the estimated population for the forecasting year?
- How are job opportunities distributed by type and category?
- What are the anticipated travel patterns in the future?
- How many trips will people make? (Trip Generation)
- Where will these trips end? (Trip Distribution)
- Which transportation mode will be utilized? (Mode Split)
- What will be the demand for different corridors, highways, and streets? (Traffic Assignment)
- Lastly, what impact will this modeled travel demand have on our area? (Rahman, 2008).
9.2 Four-step Model
According to the questions above, Transportation modeling consists of two main stages, regarding the questions outlined above. Firstly, addressing the initial four questions involves demographic and land use analysis, which incorporates the community vision collected through citizen engagement and input. Secondly, the process moves on to the four-step travel demand modeling (FSM), which addresses questions 5 through 8. While FSM is generally accurate for aggregate calculations, it may occasionally falter in providing a reliable test for policy scenarios. The limitations of this model will be explored further in this chapter.
Stage 1
In the first stage, we develop an understanding of the study area from demographic information and urban form (land-use distribution pattern). These are important for all the reasons we discussed in this book. For instance, we must obtain the current age structure of the study area, based on which we can forecast future birth rates, death, and migrations (Beimborn & Kennedy, 1996).
Regarding economic forecasts, we must identify existing and future employment centers since they are the basis of work travel, shopping travel, or other travel purposes. Empirically speaking, employment often grows as the population grows, and the migration rate also depends on a region’s economic growth. A region should be able to generate new employment while sustaining the existing ones based upon past trends and form the basis for judgment for future trends (Mladenovic & Trifunovic, 2014).
After forecasting future population and employment, we must predict where people go (work, shop, school, or other locations). Land-use maps and plans are used in this stage to identify the activity concentrations in the study area. Future urban growth and land use can follow the same trend or change due to several factors, such as the availability of open land for development and local plans and zoning ordinances (Beimborn & Kennedy, 1996). Figure 9.3 shows different possible land-use patterns frequently seen in American cities.
Land-use pattern can also be forecasted through the integration of land use and transportation as we explored in previous chapters.
Stage 2
Figure 9.3 above shows a simple structure of the second stage of FSM.
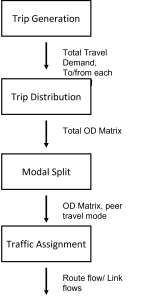
Note. Figure created by authors.
Once the number and types of trips are predicted, they are assigned to various destinations and modes. In the final step, these trips are allocated to the transportation network to compute the total demand for each road segment. During this second stage, additional choices such as the time of travel and whether to travel at all can be modeled using choice models (McNally, 2007). Travel forecasting involves simulating human behavior through mathematical series and calculations, capturing the sequence of decisions individuals make within an urban environment.
The first attempt at this type of analysis in the U.S. occurred during the post-war development period, driven by rapid economic growth. The influential study by Mitchell and Rapkin (1954) emphasized the need to establish a connection between travel and activities, highlighting the necessity for a comprehensive framework. Initial development models for trip generation, distribution, and diversion emerged in the 1950s, leading to the application of the four-step travel demand modeling (FSM) approach in a transportation study in the Chicago area. This model was primarily highway-oriented, aiming to compare new facility development and improved traffic engineering. In the 1960s, federal legislation mandated comprehensive and continuous transportation planning, formalizing the use of FSM. During the 1970s, scholars recognized the need to revise the model to address emerging concerns such as environmental issues and the rise of multimodal transportation systems. Consequently, enhancements were made, leading to the development of disaggregate travel demand forecasting and equilibrium assignment methods that complemented FSM. Today, FSM has been instrumental in forecasting travel demand for over 50 years (McNally, 2007; Weiner, 1997).
Initially outlined by Mannheim (1979), the basic structure of FSM was later expanded by Florian, Gaudry, and Lardinois (1988). Figure 9.3 illustrates various influential components of travel demand modeling. In this representation, “T” represents transportation, encompassing all elements related to the transportation system and its services. “A” denotes the activity system, defined according to land-use patterns and socio-demographic conditions. “P” refers to transportation network performance. “D,” which stands for demand, is generated based on the land-use pattern. According to Florian, Gaudry, and Lardinois (1988), “L” and “S” (location and supply procedures) are optional parts of FSM and are rarely integrated into the model.
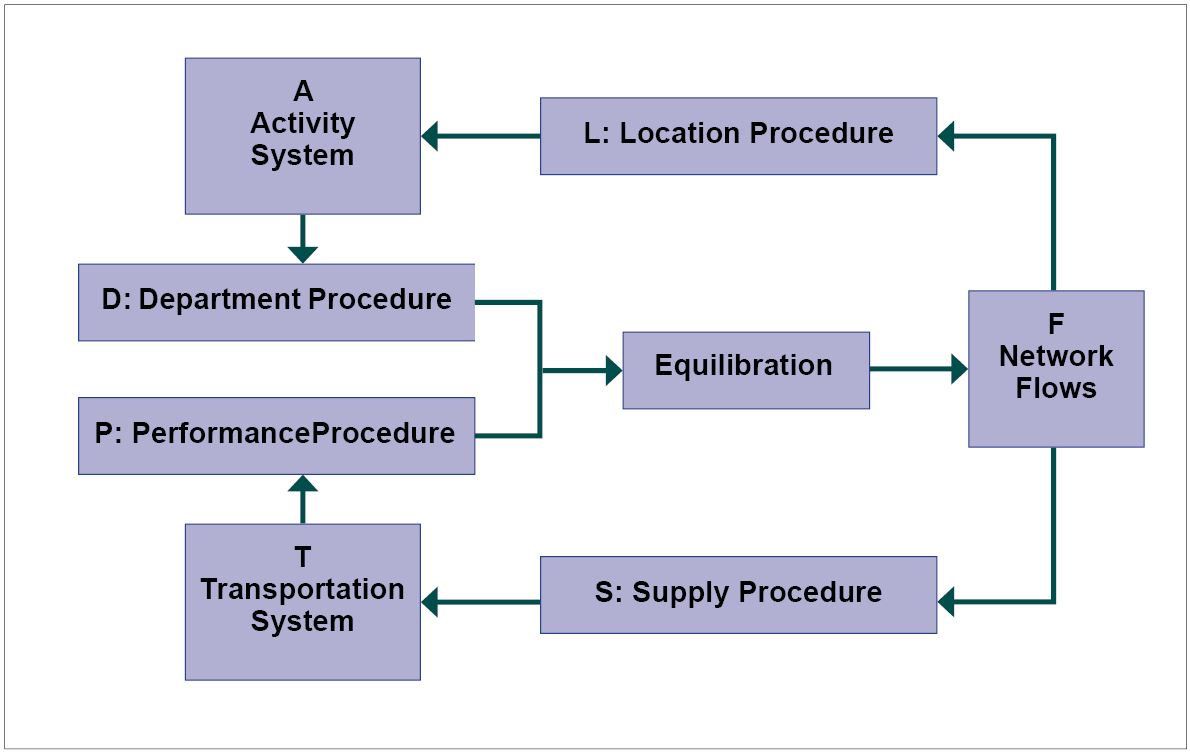
A crucial aspect of the process involves understanding the input units, which are defined both spatially and temporally. Demand generates person trips, which encompass both time and space (e.g., person trips per household or peak-hour person trips per zone). Performance typically yields a level of service, defined as a link volume capacity ratio (e.g., freeway vehicle trips per hour or boardings per hour for a specific transit route segment). Demand is primarily defined at the zonal level, whereas performance is evaluated at the link level.
It is essential to recognize that travel forecasting models like FSM are continuous processes. Model generation takes time, and changes may occur in the study area during the analysis period.
Before proceeding with the four steps of FSM, defining the study area is crucial. Like most models discussed, FSM uses traffic analysis zones (TAZs) as the geographic unit of analysis. However, a higher number of TAZs generally yield more accurate results. The number of TAZs in the model can vary based on its purpose, data availability, and vintage. These zones are characterized or categorized by factors such as population and employment. For modeling simplicity, FSM assumes that trip-making begins at the center of a zone (zone centroid) and excludes very short trips that start and end within a TAZ, such as those made by bike or on foot.
Furthermore, highway systems and transit systems are considered as networks in the model. Highway or transit line segments are coded as links, while intersections are represented as nodes. Data regarding network conditions, including travel times, speeds, capacity, and directions, are utilized in the travel simulation process. Trips originate from trip generation zones, traverse a network of links and nodes, and conclude at trip attraction zones.
Trip Generation
Trip generation is the first step in the FSM model. This step defines the magnitude of daily travel in the study area for different trip purposes. It will also provide us with an estimate of the total trips to and from each zone, creating a trip production and attraction matrix for each trip’s purpose. Trip purposes are typically categorized as follows:
- Home-based work trips (work trips that begin or end at home),
- Home-based shopping trips,
- Home-based other trips,
- School trips,
- Non-home-based trips (trips that neitherbeginnorendathome),
- Trucktrips,and
- Taxitrips(Ahmed,2012).
Trip attractions are based on the level of employment in a zone. In the trip generation step, the assumptions and limitations are listed below:
- Independent decisions: Travel behavior is affected by many factors generated within a household; the model ignores most of these factors. For example, childcare may force people to change their travel plans.
- Limited trip purposes: This model consists of a limited number of trip purposes for simplicity, giving rise to some model limitations. Take shopping trips, for example; they are all considered in the same weather conditions. Similarly, we generate home-based trips for various purposes (banking, visiting friends, medical reasons, or other purposes), all of which are affected by factors ignored by the model.
- Trip combinations: Travelers are often willing to combine various trips into a chain of short trips. While this behavior creates a complex process, the FSM model treats this complexity in a limited way.
- Feedback, cause, and effect problems: Trip generation often uses factors that are a function of the number of trips. For instance, for shopping trip attractions in the FSM model, we assume they are a retail employment function. However, it is logical to assume how many customers these retail centers attract. Alternatively, we can assume that the number of trips a household makes is affected by the number of private cars they own. Nevertheless, the activity levels of families determine the total number of cars.
As mentioned, trip generation process estimations are done separately for each trip purpose. Equations 1 and 2 show the function of trip generation and attraction:


where Oi and Dj trip are generated and attracted respectively, x refers to socio-economic characteristics, and y refers to land-use properties.
Generally, FSM aggregates different trip purposes previously listed into three categories: home-based work trips (HBW), home-based other (or non-work) trips (HBO), and non-home-based trips (NHB). Trip ends are either the origin (generation) or destination (attraction), and home-end trips comprise most trips in a study area. We can also model trips at different levels, such as zones, households, or person levels (activity-based models). Household-level models are the most common scale for trip productions, and zonal-level models are appropriate for trip attractions (McNally, 2007).
There are three main methods for a trip generation or attraction.
- The first method is multiple regression based on population, jobs, and income variables.
- The second method in this step is experience-based analysis, which can show us the ratio of trips generated frequently.
- The third method is cross-classification. Cross-classification is like the experience-based analysis in that it uses trip rates but in an extended format for different categories of trips (home-based trips or non-home-based trips) and different attributes of households, such as car ownership or income.
Elaborating on the differences between these methods, category analysis models are more common for the trip generation model, while regression models demonstrate better performance for trip attractions (Meyer, 2016). Production models are recognized to be influenced by a range of explanatory and policy-sensitive variables (e.g., car ownership, household income, household size, and the number of workers). However, estimation is more problematic for attraction models because regional travel surveys are at the household level (thus providing more accurate data for production models) and not for nonresidential land uses (which is important for trip attraction). Additionally, estimation can be problematic because explanatory trip attraction variables may usually underperform (McNally, 2007). For these reasons, survey data factoring is required prior to relating sample trips to population-level attraction variables, typically achieved via regression analysis. Table 9.1 shows the advantages and disadvantages of each of these two models.
| blank cell | Advantages | Disadvantages |
|---|---|---|
| Multiple Regression | 1. Familiar and simple-to-run procedure 2. Statistical significance calculation |
1. Linearity Assumption 2. Aggregation problem 3. Coefficients not stable over time, or after improvements 4. Multicollinearity issue |
| Category Analysis | 1. Disaggregation of data. 2. Interaction projection 3. No need for linearity assumption |
1. Needs individual level data 2. Hard to resurvey individuals for more variables 3. Best with naturally discrete variables. |
Trip Distribution
Thus far, the number of trips beginning or ending in a particular zone have been calculated. The second step explores how trips are distributed between zones and how many trips are exchanged between two zones. Imagine a shopping trip. There are multiple options for accessible shopping malls accessible. However, in the end, only one will be selected for the destination. This information is modeled in the second step as a distribution of trips. The second step results are usually a very large Origin-Destination (O-D) matrix for each trip purpose. The O-D matrix can look like the table below (9.2), in which sum of Tij by j shows us the total number of trips attracted in zone J and the sum of Tij by I yield the total number of trips produced in zone I.
Up to this point, we have calculated the number of trips originating from or terminating in a specific zone. The next step involves examining how these trips are distributed across different zones and how many trips are exchanged between pairs of zones. To illustrate, consider a shopping trip: there are various options for reaching shopping malls, but ultimately, only one option is chosen as the destination. This process is modeled in the second step as the distribution of trips. The outcome of this step typically yields a large Origin-Destination (O-D) matrix for each trip purpose. An O-D matrix might resemble the table below (9.2), where the sum of Tij by j indicates the total number of trips attracted to zone J, and the sum of Tij by I represents the total number of trips originating from zone I.
| Generations | 1 | 2 | 3 | j | .Z | ∑ Tij by j |
|---|---|---|---|---|---|---|
| 1 | T11 | T12 | T13 | T1] | T 1z | O 1 |
| 2 | T21 | T22 | T23 | T2j | T22 | O 2 |
| 3 | T31 | T32 | T33 | T3 | T3z | O 3 |
| : | : | : | : | : | : | : |
| i | Ti1 : | Ti2 : | Tr i3 : | Tij : | Tiz | O j |
| Z | Tz1 | Tz2 | Tz3 | Tzj | Tzz | O i |
| ∑ Tij by i | D 1 | D2 | D3 | D | D2 Z | ∑ Tij by I &j (total trips) |

where:
Tij = trips produced at I and attracted at j
Pi = total trip production at I
Aj = total trip attraction at j
Fij = a calibration term for interchange ij, (friction factor) or travel
time factor ( F ij =C/tij n )
C= calibration factor for the friction factor
Kij = a socioeconomic adjustment factor for interchange ij
i = origin zone
n = number of zones
Different methods (units) in the gravity model can be used to perform distance measurements. For instance, distance can be represented by time, network distance, or travel costs. For travel costs, auto travel cost is the most common and straightforward way of monetizing distance. A combination of different costs, such as travel time, toll payments, parking payments, etc., can also be used. Alternatively, a composite cost of both car and transit costs can be used (McNally, 2007).
Generalized travel costs can be a function of time divided into different segments. For instance, public transit time can be divided into the following segments: in-vehicle time, walking time, waiting time, interchange time, fare, etc. Since travelers perceive time value differently for each segment (like in-vehicle time vs. waiting time), weights are assigned based on the perceived value of time (VOT). Similarly, car travel costs can be categorized into in-vehicle travel time or distance, parking charge, tolls, etc.
As with the first step in the FSM model, the second step has assumptions and limitations that are briefly explained below.
- Constant trip times: In order to utilize the model for prediction, it assumes that the duration of trips remains constant. This means that travel distances are measured by travel time, and the assumption is that enhancements in the transportation system, which reduce travel times, are counterbalanced by the separation of origins and destinations.
- Automobile travel times to represent distance: We utilize travel time as a proxy for travel distance. In the gravity model, this primarily relies on private car travel time and excludes travel times via other modes like public transit. This leads to a broader distribution of trips.
- Limited consideration of socio-economic and cultural factors: Another drawback of the gravity model is its neglect of certain socio-economic or cultural factors. Essentially, this model relies on trip production and attraction rates along with travel times between them for predictions. Consequently, it may overestimate trip rates between high-income groups and nearby low-income Traffic Analysis Zones (TAZs). Therefore, incorporating more socio-economic factors into the model would enhance accuracy.
- Feedback issues: The gravity model’s reliance on travel times is heavily influenced by congestion levels on roads. However, measuring congestion proves challenging, as discussed in subsequent sections. Typically, travel times are initially assumed and later verified. If the assumed values deviate from actual values, they require adjustment, and the calculations need to be rerun.
Mode choice
FSM model’s third step is a mode-choice estimation that helps identify what types of transportation travelers use for different trip purposes to offer information about users’ travel behavior. This usually results in generating the share of each transportation mode (in percentages) from the total number of trips in a study area using the utility function (Ahmed, 2012). Performing mode-choice estimations is crucial as it determines the relative attractiveness and usage of various transportation modes, such as public transit, carpooling, or private cars. Modal split analysis helps evaluate improvement programs or proposals (e.g., congestion pricing or parking charges) aimed at enhancing accessibility or service levels. It is essential to identify the factors contributing to the utility and disutility of different modes for different travel demands (Beimborn & Kennedy, 1996). Comparing the disutility of different modes between two points aids in determining mode share. Disutility typically refers to the burdens of making a trip, such as time, costs (fuel, parking, tolls, etc.). Once disutility is modeled for different trip purposes between two points, trips can be assigned to various modes based on their utility. As discussed in Chapter 12, a mode’s advantage in terms of utility over another can result in a higher share of trips using that mode.
The assumptions and limitations for this step are outlined as follows:
- Choices are only affected by travel time and cost: This model assumes that changes in mode choices occur solely if transportation cost or travel time in the transportation network or transit system is altered. For instance, a more convenient transit mode with the same travel time and cost does not affect the model’s results.
- Omitted factors: Certain factors like crime, safety, and security, which are not included in the model, are assumed to have no effect, despite being considered in the calibration process. However, modes with different attributes regarding these omitted factors yield no difference in the results.
- Simplified access times: The model typically overlooks factors related to the quality of access, such as neighborhood safety, walkability, and weather conditions. Consequently, considerations like walkability and the impact of a bike-sharing program on the attractiveness of different modes are not factored into the model.
- Constant weights: The model assumes that the significance of travel time and cost remains constant for all trip purposes. However, given the diverse nature of trip purposes, travelers may prioritize travel time and cost differently depending on the purpose of their trip.
The most common framework for mode choice models is the nested logit model, which can accommodate various explanatory variables. However, before the final step, results need to be aggregated for each zone (Koppelman & Bhat, 2006).
A generalized modal split chart is depicted in Figure 9.5.
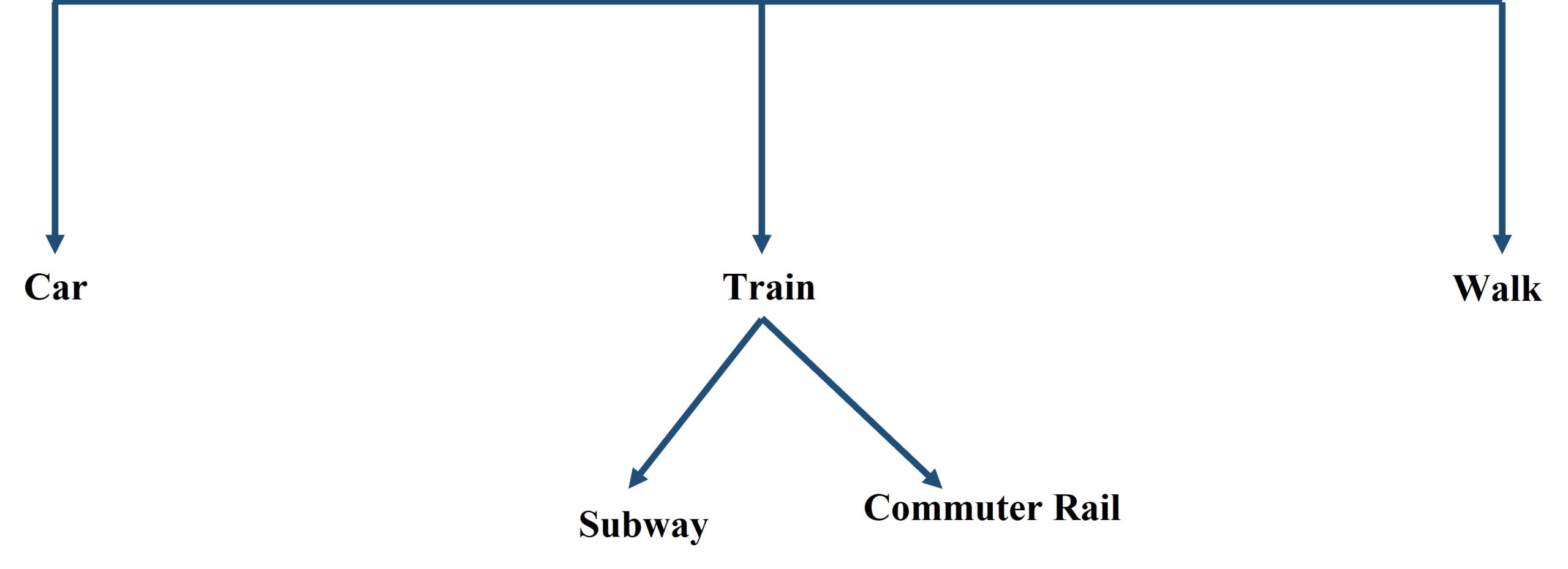
Note. Figure Created by authors.
In our analysis, we can use binary logit models (dummy variable for dependent variable) if we have two modes of transportation (like private cars and public transit only). A binary logit model in the FSM model shows us if changes in travel costs would occur, such as what portion of trips changes by a specific mode of transport. The mathematical form of this model is:

where: P_ij 1= The proportion of trips between i and j by mode 1 . Tij 1= Trips between i and j by mode 1.
Cij 1= Generalized cost of travel between i and j by mode 1 .
Cij^2= Generalized cost of travel between i and j by mode 2 .
b= Dispersion Parameter measuring sensitivity to cost.
It is also possible to have a hierarchy of transportation modes for using a binary logit model. For instance, we can first conduct the analysis for the private car and public transit and then use the result of public transit to conduct a binary analysis between rail and bus.
Trip assignment
After breaking down trip counts by mode of transportation, we analyze the routes commuters take from their starting point to their destination, especially for private car trips. This process is known as trip assignment and is the most intricate stage within the FSM model. Initially, the minimum path assigns trips for each origin-destination pair based on either travel costs or time. Subsequently, the assigned volume of trips is compared to the capacity of the route to determine if congestion would occur. If congestion does happen (meaning that traffic volume exceeds capacity), the speed of the route needs to be decreased, resulting in increased travel costs or time. When the Volume/Capacity ratio (v/c ratio) changes due to congestion, it can lead to alterations in both speed and the shortest path. This characteristic of the model necessitates an iterative process until equilibrium is achieved.
The process for public transit is similar, but with one distinction: instead of adjusting travel times, headways are adjusted. Headway refers to the time between successive arrivals of a vehicle at a stop. The duration of headways directly impacts the capacity and volume for each transit vehicle. Understanding the concept of equilibrium in the trip assignment step is crucial because it guides the iterative process of the model. The conclusion of this process is marked by equilibrium, a concept known as Wardrop equilibrium. In Wardrop equilibrium, traffic naturally organizes itself in congested networks so that individual commuters do not switch routes to reduce travel time or costs. Additionally, another crucial factor in this step is the time of day.
Like previous steps, the following assumptions and limitations are pertinent to the trip assignment step:
- Delays on links: Most traffic assignment models assume that delays occur on the links, not the intersections. For highways with extensive intersections, this can be problematic because intersections involve highly complex movements. Intersections are excessively simplified if the assignment process does not modify control systems to reach an equilibrium.
- Points and links are only for trips: This model assumes that all trips begin and finish at a single point in a zone (centroids), and commuters only use the links considered in the model network. However, these points and links can vary in the real world, and other arterials or streets might be used for commutes.
- Roadway capacities: In this model, a simple assumption helps determine roadways’ capacity. Capacity is found based on the number of lanes a roadway provides and the type of road (highway or arterial).
- Time of the day variations: Traffic volume varies greatly throughout the day and week. In this model, a typical workday of the week is considered and converted to peak hour conditions. A factor used for this step is called the hour adjustment factor. This value is critical because a small number can result in a massive difference in the congestion level forecasted on the model.
- Emphasis on peak hour travel: The model forecasts for the peak hour but does not forecast for the rest of the day. The models make forecasts for a typical weekday but neglect specific conditions of that time of the year. After completing the fourth step, precise approximations of travel demand or traffic count on each road are achieved. Further models can be used to simulate transportation’s negative or positive externalities. These externalities include air pollution, updated travel times, delays, congestion, car accidents, toll revenues, etc. These need independent models such as emission rate models (Beimborn & Kennedy, 1996).
The basic equilibrium condition point calculation is an algorithm that involves the computation of minimum paths using an all-or-nothing (AON) assignment model to these paths. However, to reach equilibrium, multiple iterations are needed. In AON, it is assumed that the network is empty, and a free flow is possible. The first iteration of the AON assignment requires loading the traffic by finding the shortest path. Due to congestion and delayed travel times, the
previous shortest paths may no longer be the best minimum path for a pair of O-D. If we observe a notable decrease in travel time or cost in subsequent iterations, then it means the equilibrium point has not been reached, and we must continue the estimation. Typically, the following factors affect private car travel times: distance, free flow speed on links, link capacity, link speed capacity, and speed flow relationship.
The relationship between the traffic flow and travel time equation used in the fourth step is:


Where
t= link travel time per length unit
t0=free-flow travel time
v=link flow
c=link capacity
a, b, and n are model (calibrated) parameters
Model improvement
Improvements to FSM continue to generate more accurate results. Since transportation dynamics in urban and regional areas are under the complex influence of various factors, the existing models may not be able to incorporate all of them. These can be employer-based trip reduction programs, walking and biking improvement schemes, a shift in departure (time of the day), or more detailed information on socio-demographic and land-use-related factors. However, incorporating some of these variables is difficult and can require minor or even significant modifications to the model and/or computational capacities or software improvements. The following section identifies some areas believed to improve the FSM model performance and accuracy.
- Better data: An effective way of improving the model accuracy is to gather a complete dataset that represents the general characteristics of the population and travel pattern. If the data is out- of-date or incomplete, we will get poor results.
- Better modal split: As you saw in previous sections, the only modes incorporated into the model are private car and public transit trips, while in some cities, a considerable fraction of trips are made by bicycle or by walking. We can improve our models by producing methods to consider these trips in the first and third steps.
- Auto occupancy: In contemporary transportation planning practices, especially in the US, some new policies are emerging for carpooling. We can calculate auto occupancy rates using different mode types, such as carpooling, sensitive to private car trips’ disutility, parking costs, or introducing a new HOV lane.
- Time of the day: In this chapter, the FSM framework discussed is oriented toward peak hour (single time of the day) travel patterns. Nonetheless, understanding the nature of congestion in other hours of the day is also helpful for understanding how travelers choose their travel time.
- A broader trip purpose: Additional trip purposes may provide a better understanding of the factors affecting different trip purposes and trip-chaining behaviors. We can improve accuracy by having more trip purposes (more disaggregate input and output for the model).
- The concept of access: As discussed, land-use policies that encourage public transit use or create amenities for more convenient walking are not present in the model. Developing factors or indices that reflect such improvements in areas with high demand for non-private vehicles and incorporating them in choice models can be a good improvement.
- Land use feedback: To better understand interactions between land use and travel demand, a land-use simulation model can be added to these steps to determine how a proposed transportation change will lead to a change in land use.
- Intersection delays: As mentioned in the fourth step, intersections in major highways create significant delays. Incorporating models that calculate delays at these intersections, such as stop signs, could be another improvement to the model.
A Simple Example of the FSM model
An example of FSM is provided in this section to illustrate a typical application of this model in the U.S. In the first phase, the specifications about the transportation network and household data are needed. In this hypothetical example, 5 percent of households in each TAZ were sampled and surveyed, which generated 1,955 trips in 200 households. As a hypothetical case study, this sample falls below the standard required for statistical significance but is relevant to demonstrate FSM.
A home interview survey was carried out to gather data from a five percent sample of households in each TAZ. This survey resulted in 1,852 trips from 200 households. It is important to note that the sample size in this example falls below the minimum required for statistical significance, as it is intended for learning purposes only.
Table 9.3 provides network information such as speed limits, number of lanes, and capacity. Table 9.4 displays the total number of households and jobs in three industry sectors for each zone. Additionally, Table 9.5 breaks down the household data into three car ownership groups, which is one of the most significant factors influencing trip making.
| blank cell | Link Type (all links 1-way) | Speed (kph) | Number of Lanes | capacity per lane | capacity (veh/hour) |
|---|---|---|---|---|---|
| 1 | freeway | 90 | 2 | 200 | 400 |
| 2 | primary arterial | 90 | 2 | 100 | 200 |
| 3 | major arterial | 60 | 2 | 100 | 200 |
| 4 | minor arterial | 45 | 2 | 100 | 200 |
| 5 | collector street | 45 | 1 | 100 | 100 |
| 6 | centroid connector | 30 | 9 | 100 | 900 |
| Internal Zone | Total Zonal Households | Total Zonal Employment | |||
|---|---|---|---|---|---|
| Retail | Service | Other | Total | ||
| 1 | 1000 | 800 | 400 | 800 | 2000 |
| 2 | 1200 | 800 | 400 | 200 | 1400 |
| 3 | 1200 | 400 | 400 | 200 | 1200 |
| 4 | 600 | 200 | 200 | 0 | 400 |
| Total | 4000 | 2000 | 1400 | 1400 | 4800 |
| blank cell | Zone 1 | Zone 2 | Zone 3 | Zone 4 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L | M | H | L | M | H | L | M | H | L | M | H | |
| 0 cars | 40 | 80 | 80 | 20 | 40 | 40 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 car | 120 | 320 | 360 | 80 | 260 | 160 | 20 | 80 | 100 | 0 | 40 | 60 |
| 2 cars | 60 | 200 | 160 | 100 | 300 | 200 | 100 | 220 | 330 | 0 | 160 | 340 |
| Example of Estimated Trip Attraction | Models |
|---|---|
| Zonal HBW Attractions = | 1.15 * Total Employment |
| Zonal HBO Attractions = | 7.30 * Retail Employment + 2 * Service Employment + 0.50 * Other Employment + 0.90 * Number of Households |
| Zonal NHB Attractions = | 4.10 * Retail Employment + 1.20 * Service Employment + 1.50 * Other Employment + 0.50 * Number of Households |
In the first step (trip generation), a category model (i.e., cross-classification) helped estimate trips. The sampled population’s sociodemographic and trip data for different purposes helped calculate this estimate. Since research has shown the significant effect of auto ownership on private car trip- making (Ben-Akiva & Lerman, 1974), disaggregating the population based on the number of private cars generates accurate results. Table 9.7 shows the trip-making rate for different income and auto ownership groups.
| Cars per HH | Household Income | HBW | HBO | NHB | Total |
|---|---|---|---|---|---|
| Cars 0
|
Low HH Income | 0.5 | 2 | 0.9 | 3.4 |
| Mid HH Income | 1.1 | 3 | 1.2 | 5.3 | |
| High HH Income | 1.4 | 3.9 | 1.8 | 7.1 | |
| Cars 1
|
Low HH Income | 0.8 | 3.2 | 1.3 | 5.3 |
| Mid HH Income | 1.5 | 3.9 | 1.6 | 7 | |
| High HH Income | 1.8 | 4.9 | 2.2 | 8.9 | |
| Cars 2
|
Low HH Income | 1.4 | 5.2 | 2.1 | 8.7 |
| Mid HH Income | 2.1 | 5.7 | 2.3 | 10.1 | |
| High HH Income | 2.5 | 6.6 | 3.1 | 12.4 |
Also, as mentioned in previous sections, multiple regression estimation analysis can be used to generate the results for the attraction model. Table 9.7 shows the equations for each of the trip purposes.
After estimating production and attraction, the models are used for population data to generate results for the first step. Next, comparing the results of trip production and attraction, we can observe that the total number of trips for each purpose is different. This can be due to using different methods for production and attraction. Since the production method is more reliable, attraction is typically normalized by production. Also, some external zones in our study area are either attracting trips from our zones or generating them. In this case, another alternative is to extend the boundary of the study area and include more zones.
| blank cell | HBW | HBO | NHB | Total | ||||
|---|---|---|---|---|---|---|---|---|
| Zone | P | A | P | A | P | A | P | A |
| 1 | 2320 | 2900 | 6464 | 9540 | 2776 | 4859 | 11560 | 17299 |
| 2 | 2122 | 2320 | 5960 | 9160 | 2530 | 4559 | 10612 | 16039 |
| 3 | 1640 | 1160 | 4576 | 3300 | 1978 | 1800 | 8194 | 6260 |
| 4 | 1354 | 580 | 3674 | 2680 | 1618 | 1359 | 6646 | 4619 |
| Total | 7436 | 6960 | 20674 | 24680 | 8902 | 12577 | 37012 | 44217 |
As mentioned, the total number of trips produced and attracted are different in these results. To address this mismatch, we can use a balance factor to come up with the same trip generation and attraction numbers if we want to keep the number of zones within our study area. Alternatively, we can consider some external stations in addition to designated zones. In this example, using the latter seems more rational because, as we saw in Table 9.4, there are more jobs than the number of households aggregately, and our zone may attract trips from external locations.
For the trip distribution step, we use the gravity model. For internal trips, the gravity model is:

where:
![a_i = \left[ \sum_j b_j A_j f(t_{ij}) \right]^{-1}](https://uta.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-13e2371abc857786859c2f81365fdc3f_l3.png "Rendered by QuickLaTeX.com")
![b_j = \left[ \sum_i a_i P_i f(t_{ij}) \right]^{-1}](https://uta.pressbooks.pub/app/uploads/quicklatex/quicklatex.com-1452ebcf1e848fd968ce9907cfe1899b_l3.png "Rendered by QuickLaTeX.com")
and f(tij) is some function of network level of service (LOS)
To apply the gravity model, we need to calculate the impedance function first, which is represented here by travel cost. Table 9.9 shows the minimum travel path between each pair of zones (skim tree) in a matrix format in which each cell represents travel time required to travel between the corresponding row and column of that cell.
Table 9.9-Travel cost table (skim tree)
| Skim tij | TAZ 1 | TAZ 2 | TAZ 3 | TAZ 4 | ES 5 | ES 6 |
|---|---|---|---|---|---|---|
| TAZ 1 | 1 | 4 | 5 | 8 | 4 | 5 |
| TAZ 2 | 4 | 2 | 9 | 7 | 5 | 4 |
| TAZ 3 | 5 | 9 | 2 | 6 | 7 | 8 |
| TAZ 4 | 8 | 7 | 6 | 3 | 7 | 6 |
| ES 5 | 4 | 5 | 7 | 7 | 0 | 4 |
| ES 6 | 5 | 4 | 8 | 6 | 4 | 0 |
Note. Table adapted from “The Four-Step Model” by M. McNally, In D. A. Hensher, & K. J. Button (Eds.), Handbook of transport modelling, Volume1, p. 5, Bingley, UK: Emerald Publishing. Copyright 2007 by Emerald Publishing.
With having minimum travel costs between each pair of zones, we can calculate the impedance function for each trip purpose using the formula

Table 9.10 shows the model parameters for calculating the impedance function for different trip purposes:
| Trip Purpose | Parameter a | Parameter b | Parameter c |
|---|---|---|---|
| Home-based Work (HBW) | 28,507 | -0.02 | -0.123 |
| Home-based Other (HBO) | 139,173 | -1.285 | -0.094 |
| Non-home-based (NHB) | 219,113 | -1.332 | -0.1 |
After calculating the impedance function, we can calculate the result of the trip distribution. This stage generates trip matrices since we calculate trips between each zone pair. These matrices are usually in “Origin-Destination” (OD) format and can be disaggregated by the time of day. Field surveys help us develop a base-year trip distribution for different periods and trip purposes. Later, these empirical results will help forecast trip distribution. When processing the surveys, the proportion of trips from the production zone to the attraction zone (P-A) is also generated. This example can be seen in Table 9.11. Looking at a specific example, the first row in table is for the 2-hour morning peak commute time period. The table documents that the production to attraction factor for the home-based work trip is 0.3. Unsurprisingly, the opposite direction, attraction to production zone is 0.0 for this time of day. Additionally, the table shows that the factor for HBO and NHB trips are low but do occur during this time period. This could represent shopping trips or trips to school. Table 9.11 table also contains the information for average occupancy levels of vehicles from surveys. This information can be used to convert person trips to vehicle trips or vice versa.
Table 9.11 Trip distribution rates for different time of the day and trip purposes
| blank cell | HBW | HBO | NHB | |||
|---|---|---|---|---|---|---|
| Period | P to A | A to P | P to A | A to P | P to A | A to P |
| 2-hr a.m. peak | 0.3 | 0 | 0.06 | 0.02 | 0.04 | 0.04 |
| 3-hr p.m. peak | 0.03 | 0.3 | 0.1 | 0.15 | 0.12 | 0.12 |
| Off-peak | 0.17 | 0.2 | 0.34 | 0.33 | 0.34 | 0.34 |
| 1-hr p.m. peak | 0.02 | 0.15 | 0.04 | 0.07 | 0.06 | 0.06 |
| Average Occupancy | 1.1 | persons/veh | 1.33 | persons/veh | 1.25 | persons/veh |
The O-D trip table is calculated by adding the multiplication of the P-to-A factor by corresponding cell of the P-A trip table and adding the corresponding cell of the transposed P-A trip table multiplied by the A-to-P factor. These results, which are the final output of second step, are shown in Table 9.12.
| Tij | TAZ 1 | TAZ 2 | TAZ 3 | TAZ 4 | ES 5 | ES 6 | Origins |
|---|---|---|---|---|---|---|---|
| TAZ 1 | 829 | 247 | 206 | 108 | 100 | 100 | 1590 |
| TAZ 2 | 235 | 725 | 104 | 158 | 100 | 100 | 1422 |
| TAZ 3 | 137 | 72 | 343 | 89 | 0 | 0 | 641 |
| TAZ 4 | 59 | 98 | 76 | 225 | 0 | 0 | 458 |
| ES 5 | 0 | 0 | 100 | 100 | 0 | 500 | 700 |
| ES 6 | 0 | 0 | 100 | 100 | 500 | 0 | 700 |
| Destinations | 1260 | 1142 | 929 | 780 | 700 | 700 | 5511 |
Once the Production-Attraction (P-A) table is transformed into Origin-Destination (O-D) format and the complete O-D matrix is computed, the outcomes will be aggregated for mode choice and traffic assignment modeling. Further elaboration on these two steps will be provided in Chapters 11 and 12.
Conclusion
In this chapter, we provided a comprehensive yet concise overview of four-step travel demand modeling including the process, the interrelationships and input data, modeling part and extraction of outputs. The complex nature of cities and regions in terms of travel behavior, the connection to the built environment and constantly growing nature of urban landscape, necessitate building models that are able to forecast travel patterns for better anticipate and prepare for future conditions from multiple perspectives such as environmental preservation, equitable distribution of benefits, safety, or efficiency planning. As we explored in this book, nearly all the land-use/transportation models embed a transportation demand module or sub model for translating magnitude of activities and interconnections into travel demand such as VMT, ridership, congestion, toll usage, etc. Four-step models can be categorized as gravity-based, equilibrium-based models from the traditional approaches. To improve these models, several new extensions has been developed such as simultaneous mode and destination choice, multimodality (more options for mode choice with utility), or microsimulation models that improve granularity of models by representing individuals or agents rather than zones or neighborhoods.
Glossary
- Travel demand modeling are models that predicts the flow of traffic or travel demand between zones in a city using a sequence of steps.
- Intermodality refers to the concept of utilizing two or more travel modes for a trip such as biking to a transit station and riding the light rail.
- Multimodality is a type of transportation network in which a variety of modes such as public transit, rail, biking networks, etc. are offered.
- Zoning ordinances is legal categorization of land use policies that permits or prohibits certain built environment factors such as density.
- Volume capacity ratio is ratio that divides the demand on a link by the capacity to determine the level of service.
- Zone centroid is usually the geometric center of a zone in modeling process where all trips originate and end.
- Home-based work trips (HBW) are the trips that originates from home location to work location usually in the AM peak.
- Home-based other (or non-work) trips (HBO) are the trips that originates from home to destinations other than work like shopping or leisure.
- Non-home-based trips (NHB) are the trips that neither origin nor the destination are home or they are part of a linked trip.
- Cross-classification is a method for trip production estimation that disaggregates trip rates in an extended format for different categories of trips like home-based trips or non-home-based trips and different attributes of households such as car ownership or income.
- Generalized travel costs is a function of time divided into sections such as in vehicle time vs. waiting time or transfer time in a transit trip.
- Binary logit models is a type of logit model where the dependent variable can take only a value of 0 or 1.
- Wardrop equilibrium is a state in traffic assignment model where are drivers are reluctant to change their path because the average travel time is at a minimum.
- All-or-nothing (AON) assignment model is a model that assumes all trips between two zones uses the shortest path regardless of volume.
- Speed flow relationship is a function that determines the speed based on the volume (flow)
- skim tree is structure of travel time by defining minimum cost path for each section of a trip.
Key Takeaways
In this chapter, we covered:
- What travel demand modeling is for and what the common methods are to do that.
- How FSM is structured sequentially, what the relationships between different steps are, and what the outputs are.
- What the advantages and disadvantages of different methods and assumptions in each step are.
- What certain data collection and preparation for trip generation and distribution are needed through a hypothetical example.
Prep/quiz/assessments
- What is the need for regular travel demand forecasting, and what are its two major components?
- Describe what data we require for each of the four steps.
- What are the advantages and disadvantages of regression and cross-classification methods for a trip generation?
- What is the most common modeling framework for mode choice, and what result will it provide us?
- What are the main limitations of FSM, and how can they be addressed? Describe the need for travel demand modeling in urban transportation and relate it to the structure of the four-step model (FSM).
References
Ahmed, B. (2012). The traditional four steps transportation modeling using a simplified transport network: A case study of Dhaka City, Bangladesh. International Journal of Advanced Scientific Engineering and Technological Research, 1(1), 19–40. https://discovery.ucl.ac.uk/id/eprint/1418961/
ALMEC, C. (2015). The Project for capacity development on transportation planning and database management in the republic of the Philippines: MMUTIS update and enhancement project (MUCEP) : Project Completion Report. Japan International Cooperation Agency. (JICA) Department of Transportation and Communications (DOTC) . https://books.google.com/books?id=VajqswEACAAJ.
Beimborn, E., and Kennedy, R. (1996). Inside the black box: Making transportation models work for livable communities. Washington, DC: Citizens for a Better Environment and the Environmental Defense Fund. https://www.piercecountywa.gov/DocumentCenter/View/755/A-GuideToModeling?bidId
Ben-Akiva, M., & Lerman, S. R. (1974). Some estimation results of a simultaneous model of auto ownership and mode choice to work. Transportation, 3(4), 357–376. https://doi.org/10.1007/bf00167966
Ewing, R., & Cervero, R. (2010). Travel and the built environment: A meta-analysis. Journal of the American Planning Association, 76(3), 265–294. https://doi.org/10.1080/01944361003766766
Florian, M., Gaudry, M., & Lardinois, C. (1988). A two-dimensional framework for the understanding of transportation planning models. Transportation Research Part B: Methodological, 22(6), 411–419. https://doi.org/10.1016/0191-2615(88)90022-7
Hadi, M., Ozen, H., & Shabanian, S. (2012). Use of dynamic traffic assignment in FSUTMS in support of transportation planning in Florida. Florida International University Lehman Center for Transportation Research. https://rosap.ntl.bts.gov/view/dot/24925
Hansen, W. (1959). How accessibility shapes land use.”Journal of the American Institute of Planners 25 (2): 73–76. https://doi.org/10.1080/01944365908978307
Gavu, E. K. (2010). Network based indicators for prioritising the location of a new urban transport connection: Case study Istanbul, Turkey (Master’s thesis, University of Twente). International Institute for Geo-Information Science and Earth Observation Enschede. http://essay.utwente.nl/90752/1/Emmanuel%20Kofi%20Gavu-22239.pdf
Karner, A., London, J., Rowangould, D., & Manaugh, K. (2020). From transportation equity to transportation justice: Within, through, and beyond the state. Journal of Planning Literature, 35(4), 440–459. https://doi.org/10.1177/0885412220927691
Kneebone, E., & Berube, A. (2013). Confronting suburban poverty in America. Brookings Institution Press.
Koppelman, Frank S, and Chandra Bhat. (2006). A self instructing course in mode choice modeling: multinomial and nested logit models. U.S. Department of Transportation Federal Transit Administration https://www.caee.utexas.edu/prof/bhat/COURSES/LM_Draft_060131Final-060630.pdf
Manheim, M. L. (1979). Fundamentals of transportation systems analysis. Volume 1: Basic Concepts. The MIT Press https://mitpress.mit.edu/9780262632898/fundamentals-of-transportation-systems-analysis/
McNally, M. G. (2007). The four step model. In D. A. Hensher, & K. J. Button (Eds.), Handbook of transport modelling, Volume1 (pp.35–53). Bingley, UK: Emerald Publishing.
Meyer, M. D., & Institute Of Transportation Engineers. (2016). Transportation planning handbook. Wiley.
Mladenovic, M., & Trifunovic, A. (2014). The shortcomings of the conventional four step travel demand forecasting process. Journal of Road and Traffic Engineering, 60(1), 5–12.
Mitchell, R. B., and C. Rapkin. (1954). Urban traffic: A function of land use. Columbia University Press. https://doi.org/10.7312/mitc94522
Rahman, M. S. (2008). “Understanding the linkages of travel behavior with socioeconomic characteristics and spatial Environments in Dhaka City and urban transport policy applications.” Hiroshima: (Master’s thesis, Hiroshima University.) Graduate School for International Development and Cooperation. http://sr-milan.tripod.com/Master_Thesis.pdf
Rodrigue, J., Comtois, C., & Slack, B. (2020). The geography of transport systems. London ; New York Routledge.
Shen, Q. (1998). Location characteristics of inner-city neighborhoods and employment accessibility of low-wage workers. Environment and Planning B: Planning and Design, 25(3), 345–365.
Sharifiasl, S., Kharel, S., & Pan, Q. (2023). Incorporating job competition and matching to an indicator-based transportation equity analysis for auto and transit in Dallas-Fort Worth Area. Transportation Research Record, 03611981231167424. https://doi.org/10.1177/03611981231167424
Weiner, Edward. 1997. Urban transportation planning in the United States: An historical overview. US Department of Transportation. https://rosap.ntl.bts.gov/view/dot/13691
. Taking the Guesswork out of Designing for Walkability. Planetizen. https://www.planetizen.com/node/63248
Travel demand modeling are models that predicts the flow of traffic or travel demand between zones in a city using a sequence of steps.
Zoning ordinances is legal categorization of land use policies that permits or prohibits certain built environment factors such as density.
Volume capacity ratio is ratio that divides the demand on a link by the capacity to determine the level of service.
Home-based work trips (HBW) are the trips that originates from home location to work location usually in the AM peak.
Home-based other (or non-work) trips (HBO) are the trips that originates from home to destinations other than work like shopping or leisure.
Non-home-based trips (NHB) are the trips that neither origin nor the destination are home or they are part of a linked trip.
Cross-classification is a method for trip production estimation that disaggregates trip rates in an extended format for different categories of trips like home-based trips or non-home-based trips and different attributes of households such as car ownership or income.
gravity model is a type of accessibility measurement in which the employment in destination and population in the origin defines thee degree of accessibility between the two zones.
Binary logit models is a type of logit model where the dependent variable can take only a value of 0 or 1.
All-or-nothing (AON) assignment model is a model that assumes all trips between two zones uses the shortest path regardless of volume.
Speed flow relationship is a function that determines the speed based on the volume (flow)
skim tree is structure of travel time by defining minimum cost path for each section of a trip.
Impedance function is a function that convert travel costs (usually time or distance) to the level of difficulty of getting from one location to the other.
