Fundamentals of database design
The first step in the formal process of database design is to identify the principal purpose(s) the database will serve. There are three functions that are likely to be of interest to a historian:
- Data management
- Record linkage
- Aggregate analysis and recognition of patterns.
While these functions are not mutually exclusive, each is effected by design considerations. Often you will not fully know what you want to do with the database at the beginning of the design process, which is ideally the best time to be making these important decisions. Flexibility is therefore another important concept to remember.
Each of these functions is a goal that can be achieved through shaping of the database in the design process, and each will require some elements of the database design to be conducted in specific ways, although they are by no means mutually exclusive. And this latter point is an important one, given that most historians will want to have access to the full range of functionality offered by the database, and will likely engage in research that will require all three of the listed types of activity. Or, to put it another way, you are unlikely to know precisely what it is you to do with your database at the very beginning of the design process, which is when these decisions should be taken. This is why many historians design databases which maximize flexibility in what they can use them for later on in the project (a goal comes at the price of design simplicity).
Sometimes historians use the database as a bibliographic resource as well. It can be useful to connect notes from secondary sources to primary sources and trace these connections in either direction.
The power of a relational database, which is the power of record-linkage, is closely associated with and even dependent upon the database design. Efficiency and accuracy are dictated by the structure of the database and the data model. The more that you expect to perform counting, averaging, summing or other forms of aggregation of your data, the more thought and effort you should put into the design of your data model and the application of a standardization layer to your data.
Conceptual models of database design
The two conceptual models of database design are known as:
- The Source-oriented approach (sometimes called the Object-oriented approach)
- The Method-oriented approach.
These two approaches are diametric opposites. Every database design is a compromise between these two. There is no perfect, absolute method-oriented database, nor is there a perfect, absolute source-oriented database.
The Source-oriented model of database design requires that everything about the design of the database is geared towards recording every last piece of information from the sources, omitting nothing, and in effect becoming a digital proxy for the original. The information contained within the sources, and the shape of that information, completely dictates how the database must be structured.
The lifecycle of an ideal source-oriented database can be represented thus:
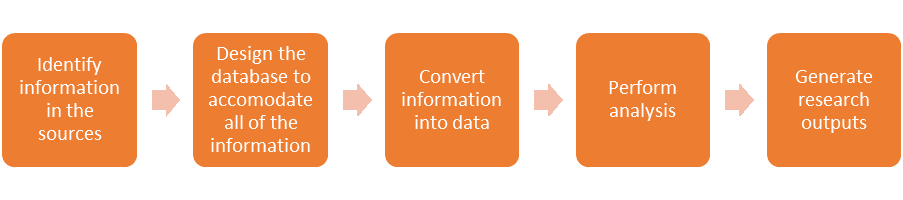
Lifecycle of the Source-oriented database
Historians gravitate toward this method because it places the sources at the center of the database project. Data entry into a database is a very time-consuming activity, however; this is exacerbated when you are painstakingly recording all of the information that exists in your sources. In practical terms, you must make choices about which information to exclude from the database, contrary to the principles of the Source-oriented model. This violates the database’s role as a digital surrogate for your sources but at least allows you to perform your research within a reasonable period.
A rigorously applied Source-oriented approach can result in an unwieldy design when you try to accommodate every piece of information from your source – some of which may only occur once. True, it does permit greater latitude in later analytical approaches, so that queries are not limited to the initial research agenda. It allows you the luxury of not having to anticipate all of your research questions in advance, which the Method-oriented model does require. The Source-oriented model conveys the source (with all its oddities and irregularities) in a reasonably reliable way into the database with minimal loss of information – ‘everything’ is recorded (i.e., what is excluded is done so by your conscious choice), and if later something becomes interesting, you do not have to return to the source to enter information that you did not initially deem interesting. The Source-oriented model also enables you to record information from the source ‘as is’, and lets you take decisions about meaning later – so ‘merc.’ can be recorded as ‘merc.’, and not expanded to ‘merchant’ or ‘mercer’ at the point of entry into the database.1
By contrast, the lifecycle of the Method-oriented model database could be represented in a different way:
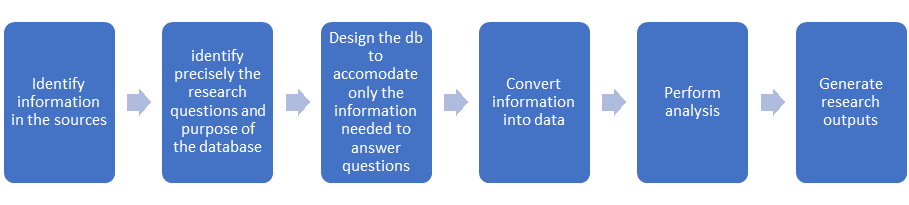
Lifecycle of the Method-oriented database
Here the focus is on function and output, rather than the nature of the information itself. Therefore, in choosing his model for your database, it is absolutely imperative that you know from the start exactly what you will want to do with the database – including what queries you will want to run. Do not underestimate the precision needed here; the database requires a high degree of granularity to perform analysis.
Method-oriented databases are quicker to design, build, and enter data into; however, it is difficult and time-consuming to deviate away from the designed function of the database, in order to explore newly discovered lines of investigation.
Ultimately, you will need to steer a middle course between the two models, probably with a tendency to lean towards the Source-oriented approach. When making decisions about what information you need from your sources to go into the database, remember that your needs may change over the course of a project which might take a number of years. If you want to be able to maintain maximum flexibility in your research agenda, then plan to accommodate more information in the database design than if you are very clear on what it is you need to do and are confident that it will never change. If you do not know whether your research needs will change, err on the side of accommodating more information – do not exclude information about servants or slaves unless you are absolutely sure that you will never want to treat ‘households with servants’ and ‘households with slaves’ as units of analysis; if you have not entered that information, then it will not be there to query later on.
However, if you are very clear about your goals and thoroughly familiar with the sources and do not expect a long-term use of this information, a Method-oriented model can be useful, efficient, and far faster to use. If you are answering a few well-defined, specific questions, the Method-oriented model makes more sense.
Database layers
Databases often involve several stages of work before they can be fully utilized for analysis. This is because well designed databases arrange data into several layers. The ‘Three Layer’ model of database design serves to illustrate how the organization of different types of data within a database can dramatically improve the analytical potential of that database. The Standardization Layer in particular is one that historians should invest time and effort into developing.
You should always be able to identify whether a piece of data is from the source or whether it has been standardized in some way by you. In terms of database structure, every field will always belong to one layer only, although tables can contain fields from any combination of layers.
- The Source layer
- This layer includes the tables and fields that contain information taken from the source and the forms of the data which have been entered verbatim from the original. No adaptation of the original information has taken place in this layer. This allows you to retrieve information that shows what the source actually said.
- The Standardization layer
- This layer includes the tables and fields which contain data that you have adapted to make analysis easier, and includes data where spelling has been standardized, where abbreviations have been expanded, where a single dating system is used and so on. This layer may be created at the database design stage or later, after data entry is complete. If entering standardized data at data entry time, then you must be rigorously consistent in the way that you enter your standardized forms (e.g. always spelling ‘Thomas’ in the same way), and you should document how you have standardized. If standardization is performed after data entry as post-processing, you can create your standardized values globally across the entire body of data; this can be time consuming when dealing with lots of information that needs to be standardized. If possible, the former approach is almost always the better option to take.
- The Interpretation or Enrichment layer
- This layer is optional, while the other two are not. In this layer is data and material from elsewhere, not the primary sources. This can include classification, interpretation, or calculated variables. It can be the means of linking together several components or chunks of information to create a larger encyclopedic record. Many research databases do not include an Interpretation layer.
Usually these layers do not exit separately as discrete collections of data. In most cases data belonging to the layers will co-exist within tables, but within separate fields within the tables: for example you might create two fields for ‘occupation’ in the same table that records information about people, in one field belonging to the Source layer you can record how the occupation is presented in the source, in the second field belonging to the Standardization layer you can record a standardized version of the occupation. The standardized version will be used for querying and analysis, because it will be easier to find.
Database definitions: tables, fields, records, values, rules, and datatypes
Harvey and Press provide a definition of a database:
“A database is a collection of inter-related data organized in a pre-determined manner according to a set of logical rules, and is structured to reflect the natural relationships of the data and the uses to which they will be put, rather than reflecting the demands of the hardware and software.”
This is a useful way of describing both the content and environment of a database. Within the database itself, however, are a number of different ‘things’, called Objects, which serve a variety of functions (these include tables where the actual data is stored, queries, user interfaces and so on). For the moment we will concentrate on only the first of these objects, the tables, and we will look at some of the terms connected with them.
There are four main elements to any table in a database, and each of these have a number of names:
- Table (also known as Entities)
- Field name (also known as the Attribute name or Column name)
- Field (also variously known as Column, Variable, Attribute) This is the value in the field.
- Record (also known as Row) The collection of all the fields makes a record.

In each database, data are stored in tables, and most databases will have more than one table. These tables will have relationships between them which connect the information they contain and will thus be ‘relational’. Tables are made up of fields (columns) and records (rows). Each field contains one type of information, and for each record the information in that field will be of the same kind.
Primary and Foreign Keys
Primary and Foreign Keys serve as the anchors for the connections among related tables. The keys serve a particular purpose within a table: usually they are not used to capture information drawn for the sources, but instead they are used to keep track of the information needed for the database to know which records in one table are connected to records in a related table.
A rule of database design states that ‘each complete record must be unique’. With historical sources, this can sometimes be a problem. Often the same information legitimately appears multiple times in the sources, for example, when an individual is named as a witness to a number of wills across a decade or the same person is arrested more than once. To ensure that the records adhere to the requirement for uniqueness, it is necessary to guarantee that each record will be distinct; if the nature of our historical information prevents us from being able to guarantee this, we are forced to cheat. Surprisingly, in doing so, we actually achieve a number of useful effects in the design of our tables.
The easiest way to guarantee that each record is unique is to add a field into which we enter (or let the database enter automatically) a unique identifier, a value which will be different for every record added to the table. Typically, this is a sequential number, such as the values in the various ID fields in the People and Cars database. A sequential number value applied to each record will ensure by itself that every record as a whole will be unique – because the ID value is never be duplicated from one record to the next.
This unique field serves as the Primary Key field for a table, this being the field that acts as the connector for the ‘one’ side of a one-to-many relationship. The field that connects the other side of the relationship that exists in the table on the ‘many’ side of the relationship is known as the Foreign Key. A Foreign Key field does not contain a unique value for every record: because it is on the many side of the relationships, the same ID value is likely to occur in more than one record.
Consider the People and Cars database:
Person table:
|
PersonID |
FirstName |
LastName |
DoB |
DoD |
Race |
Location |
Gender |
|
1 |
Anthony |
Soprano |
1/22/1958 |
11/15/2003 |
White |
New Jersey |
Male |
|
2 |
John |
Snow |
2/15/1998 |
|
White |
Winterfell |
Male |
|
3 |
Scarlett |
O’Hara |
5/16/1842 |
3/10/1931 |
White |
Tara |
Female |
|
4 |
Sherlock |
Holmes |
6/29/1859 |
4/4/1940 |
White |
London |
Male |
|
5 |
George |
Jefferson |
1/1/1956 |
12/20/2004 |
Black |
New York |
Male |
|
6 |
Louise |
Jefferson |
3/3/1960 |
10/8/2010 |
Black |
New York |
Female |
|
7 |
Laverne |
Cox |
7/5/1981 |
|
Black |
New Jersey |
|
|
8 |
Lucille |
Ricardo |
9/19/1930 |
1/5/2004 |
White |
New York |
Female |
|
9 |
Ricky |
Ricardo |
10/1/1926 |
1/20/1989 |
Hispanic |
Cuba |
Male |
|
10 |
Fred |
Mertz |
11/1/1905 |
1/2/1975 |
White |
NYC |
Male |
|
11 |
Ethel |
Mertz |
11/5/1912 |
6/30/1990 |
White |
New York City |
Female |
Car table:
|
PersonID |
CarID |
CarType |
CarMake |
CarModel |
CarColor |
|
1 |
1 |
Sedan |
Honda |
Accord |
Black |
|
2 |
2 |
Coupe |
Honda |
Civic |
Red |
|
3 |
3 |
SUV |
Nissan |
Rogue |
White |
|
4 |
4 |
SUV |
Cadillac |
Esplanade |
Silver |
|
5 |
4 |
SUV |
Cadillac |
Esplanade |
Silver |
|
6 |
5 |
SUV |
Ford |
Escape |
Blue |
|
7 |
6 |
Convertible |
Volkswagen |
Golf |
Gold |
|
7 |
8 |
Sedan |
Ford |
Taurus |
Green |
|
8 |
7 |
Sedan |
Pontiac |
Bonneville |
Aqua |
|
9 |
7 |
Sedan |
Pontiac |
Bonneville |
Aqua |
The relationship is one-to-many, a person can have many cars, and the relationship is connected by the PersonID field which is present in both tables. The PersonID field is the Primary Key of the Person table, being unique in that table. It is a Foreign Key in the Car table, appearing multiple times. The same PersonID will appear every time a record contains a car owned by that person (as is the case for person 7).
When designing the database, you need to think about what fields will appear in your tables, and you should remember to identify the Primary and Foreign Keys for your tables. Every table should have a Primary Key field – a field with the datatype ‘autonumber’ which will generate a unique value for every new record you add. Not every table will have a Foreign Key field, only those that are on the ‘many’ side of a one-to-many relationship. Remember that the Foreign Key field will contain the same information (that is, the ID numbers) drawn from the field that is the Primary Key for that relationship. Without these Key fields, the database is unable to correctly manage the relationship, which makes retrieval and analysis of information virtually impossible.
