Introduction
Most of the issues you will face arise through the variability and ambiguity that inevitably accompanies the information found in historical sources. Historians are rarely able to confidently predict the nature of their information, even if they know their sources intimately; there will almost always be instances where the sources confound us. These can be in the form of extra information in the material which seems to be outside the scope of the source, or missing or illegible text, or through marginalia, deletions and so on.
Chronology, topography, geography, orthography, and a range of other historical contexts introduce an element of ‘fuzziness’ into the data; fuzziness is kryptonite the relational database model. The irregularity of historical information must be managed through the design of the database in order to achieve a balance between maintaining the detail and richness of the source to the degree the project needs, while simultaneously standardizing and reshaping the information enough to allow the database to operate with maximum efficiency and flexibility.
Problematic information
There are certain categories of historical information which are habitually problematic, and unfortunately these tend to be those subjects that often constitute analytical units, namely geography, chronology and orthography.
Geographical information
The problem with geographical information that occurs in historical sources is that the boundaries of administrative units overlap and change over time, so that the same physical location can belong to different counties/parishes/wards/precincts and so on depending upon the date of the source being consulted. If your sources cover an extensive time range, you will need to be sensitive to the implications that boundary changes in that period may have for your data. This is especially true if you are recording data in a hierarchical fashion: for example, if you have a field in a table for ‘Parish’, and another for ‘County’, and every record will be given a value in each field. If the parish of St Bilbo Baggins is situated in the county of Hobbitonshire at the beginning of the 17th century, then records connected with this parish would have these two values entered into the respective fields in the table. If, however, administrative changes in the 18th century alter the county boundaries so that St Bilbo Baggins suddenly belongs to the county of Breeshire, then the records will have the values of St Bilbo Baggins in the parish field, and Breeshire in the county field. Whilst this is accurate, it suddenly causes a problem for the database, in that you will have a number of records with the same string in the ‘Parish’ field – and so will be recognized by the database as meaning exactly the same thing – but which historically speaking have different meanings at different points in time.
In this instance there are various ways of dealing with this issue. You simply stay aware of the problem, and when running queries on parishes you take the ‘County’ field into account as well as the ‘Parish’ field. This will enable you to specify which version of the parish of St Bilbo Baggins you are analyzing. Secondly, you could modify the Parish value to specify which version it is, so instead of entering St Bilbo Baggins, you could enter St Bilbo Baggins: Hobbitonshire or St Bilbo Baggins : Breeshire into the Parish field. This would simplify the complication of running queries in this situation, but it would technically break the database rule about ‘atomic.
This problem is even more significant when it is not just the geographical boundaries that change, but when the actual entities themselves change. For example, 17th century London had over 100 parishes in the early part of the century, many of them absolutely tiny in terms of area and population. After the Great Fire, these were reorganized, with the result that many were merged or united; In some cases, the newly created entity retained the name of one of the pre-Fire parishes, while each parish still maintained its own existence for some administrative purposes (eg. St Martin Ironmonger Lane and St Olave Jewry). Here the problem is not one of changing hierarchy (which parish belongs to which county), but one of meaning (what area/population is the source referring to at this date when referring to ‘St Martin Ironmonger’?). Various approaches to solving this are used, including that for the preceding example. The most important thing is to be clear in the data at all times precisely what is meant by the geographical terms you enter into the database.
Chronological/dating information
All of the possible problems created by shifting geographical terminology apply to the identification of dates in historical data. This is clearly a more serious issue the further back in history your sources were generated, when calendars and dating systems were more varied and plentiful, and record-keepers had more of a choice in what dating system they could choose. The important thing to remember here, as with geography (and indeed everything else entered into the database), is that the database does not recognize meaning. The database does not interpret when the ‘Tuesday after the Feast of the Blessed Assumption in the third year of Richard II’ was. That date, as a value, cannot be stored, sorted, or queried as date DataType. Regnal years, mayoral years, feast days, the days of fairs and markets etc. need to be converted into a value that uses an actual modern date format. In addition, there is the issue of the shift from Julian to Gregorian calendars. Depending on the span of time and the geo-political source of the records this fact may need to be considered. This does not necessarily literally mean ‘convert’: it would be entirely reasonable if your research required it to have two fields to enter date information, one that contained the date verbatim from the source, and the second into which the modern rendering could be entered. Querying and sorting could then take place using the latter field
Do not forget the datatype of the field into which dating information will be entered, bearing in mind that ‘Text’ datatype fields will sort dates alphabetically whereas ‘Date/Time’ datatype fields will sort them chronologically.
Orthography/variant forms
This is the really big area in which historical sources provide information that is problematic for the database: how do you deal with information that appears with many different spellings or in entirely different forms when in reality it means the same thing (or at least you wish to treat it as the same thing)? How will you deal with contractions and abbreviations, particularly when they are not consistent in the source? How will you accommodate information that is incomplete, or is difficult to read or understand where you are uncertain about its meaning? All of these issues are practically certain to crop up at some point in the data entry process, and all of them will need to be addressed to some extent to prevent problems and inaccuracies arising during the analysis of your data.
Standardization, classification, and coding
The principal way forward for accommodating data containing these kinds of problems is to apply (often quite liberally) a Standardization layer into the design of the database through the use of Standardization, classification and coding. These three activities are a step removed from simply gathering and entering information derived from the sources: this is where we add (or possibly change) information in order to make retrieving information and performing analysis easier. We use these techniques to overcome the problem of information that means the same thing appearing differently in the database, which prevents the database from connecting like with like (the fundamental pre-requisite for analyzing data). For historians this is a more important step than for other kinds of database users, because the variety of forms and ambiguity of meaning of our sources does not sit well with the exactitude required by the database (as with the example of trying to find all of our records about John Smith, so that more of a Standardization layer needs to be implemented.
Standardization, classification and coding are three distinct techniques which overlap, and most databases will use a combination of the three when adding a Standardization layer into the design:
Standardization
This is the process of deciding upon one way of representing a piece of information that appears in the source in a number of different ways (e.g. one way of spelling place/personal names; one way of recording dates and so on) and then entering that standardized version into the table. Consider using Standardization when dealing with values that appear slightly different, but mean the same thing – ‘Ag Lab’ and ‘Agricultural Labour’ as values would be treated very differently by the database, so if you wanted them to be considered as the same thing, you would signal this to the database by giving each record with a variant of this occupation the same standardized value.
Classification
This is the process of grouping together information (‘strings’) according to some theoretical, empirical or entirely arbitrary scheme, often using a hierarchical system in order to improve analytical potential. Classification is about identifying groups, and then assigning your data to those groups. These groups can be hierarchical, and the hierarchy will let you perform your analysis at a variety of levels. Classification is less about capturing the information in your sources and is much more about serving your research needs.
Classification is usually independent of the source information. It is something meaningful to you and your research purposes and is arbitrarily applied to meet your needs and methods. Consistent application will lead to more efficient use and more accurate results.
If you are investigating sources that previous historians have used, there may already exists the arbitrary classification system devised by others. You may want to use the same classification system for the advantage of not having to reinvent that component as well as for ease of comparison to the work of others. But do not feel that you cannot devise your own classifications. These can be in addition to the previous classification or can be modification or extensions to those previous schemes.
An example of a classification system can be observed in an ongoing project that investigates the material aspects of early modern households; this project uses a database to record minutely detailed information about material objects. One of the ways it treats the information about objects is to classify objects by type, in order to be able to compare like objects despite the often substantial differences in the ways they are referred to in the sources. This works by adding a field in the table where item type data is recorded into which an ItemClass code value can be added:
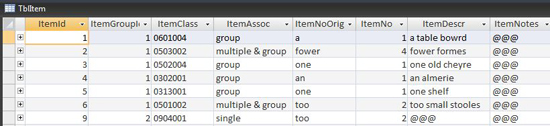
Data about material objects that have been classified and coded
The ItemClass field here is populated with codes, and these codes record precisely what type of item the record is about (you can see what the source calls the item in the ItemDescr field).[2] The fact that the code is a numeric value, and the fact that the same numeric code is applied to the same type of object regardless of how it is described in the source, means that the ItemClass field acts as a standardized value. This is a foreign key into a supporting look-up or classification table.
Additionally, however, the ItemClass field enables the use of a hierarchical classification system. The hierarchy operates by describing objects at three increasingly detailed levels:
Code I: the broadest level (for example, Linen (household); Storage; Tools; Clothing – Outer; Lighting etc.)
Code II: the middle level, offering sub-groups of Code I (for example Tools > Domestic implements; Clothing – Outer > Footwear)
Code III: the most detailed level of description (for example Clothing – Outer > Footwear > Boots)
To illustrate this we can take the example of how the database classifies objects that are used for seating:
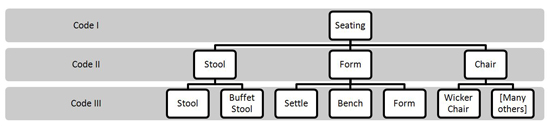
Classification system for objects in the category of ‘Seating’
Each code level has a two or three digit numeric code, so Code I: Seating has the numeric code 05, that for Code II: Chair is 02, and that for Code III: Wicker Chair is 006. These individual codes become elided into a single numeric code (in the case of the wicker chair – 0502006) which is the value that gets entered into the relevant single field (ItemClass) in the record for the wicker chair in the database.
This may sound complicated and slow to implement, but the benefit of doing so is considerable. The database can be designed so that these codes are automatically available as ‘look-up’ values. These can be selected at the time of data entry rather than having to be memorized. Secondly, once the data have been coded, they can be analyzed at three different semantic levels. You could analyze all instances of wicker chairs in the database by running queries on all records which had the ItemClass value “0502006”. Or, if you were interested in analyzing the properties of all the chairs in the database, they could do so by running queries on all records with an ItemClass value that begins “0502***”. Lastly, if the point of the research was to look at all objects used for seating, a query could be designed to retrieve all records with an ItemClass value that began “05*****”. This is an immensely powerful analytical tool, which would be difficult to achieve without the use of a hierarchical classification system: to run a query to find all objects used for seating without a classification system would require looking for each qualifying object that the historian can anticipate or remember, by name and taking into account the variant spellings that might apply.[3]
Hierarchical classification systems are very flexible things as well. They can include as many levels as you require to analyze your data, and they do not need to employ numeric codes when simple standardized text would be easier to implement.
Coding
Coding is the process of substituting (not necessarily literally) one value for another, for the purpose of recording a complex and variable piece of information through a short and consistent value. Coding is often closely associated with classification, and in addition to saving time in data entry (it is much quicker to type a short code word than it is to type five or six words) codes additionally act as Standardization (that is, the same form is entered for the same information no matter how the latter appears in the source). These are related one-to-many look-up tables. For example, think of typing TX or TN instead of Texas or Tex but the database can consistently display Texas in output by means of the related look-up table.
These techniques are implemented to make the data more readily useable by the database: the codes, classifications and standardized forms which are used are simple and often easier to incorporate in to a query design than the complicated and incomplete original text strings that appear in the source; but more importantly, they are consistent, making them much easier to find. However there are a number of things to bear in mind when using them, the most important of which is there are two ways of applying these techniques:
By replacing original values in the table with standardized/coded/classified forms
By adding standardized/coded/classified forms into the table alongside the original values
Each of these approaches are a compromise between maintaining integrity of the sources and improving efficiency of analysis. The first approach to standardizing, to replace the original version of source information in any chosen field(s) with standardized forms of data, enables the speeding up of data entry at the expense of losing what the source says. It also serves as a type of quality control, as entering standardized data (especially if controlled with a ‘look-up list’) is less prone to data entry errors than the original forms that appear in the source.
The second approach, to enter standardized values in addition to the original forms, allows for the best of both worlds: you achieve the accuracy and efficiency benefits of Standardization without losing the information as it is presented in the source. Of course, this happens at the cost of extra data inputting time, as you enter material twice.
When considering both approaches, bear in mind that you will only need to standardize some of the fields in your tables, not every field in every table. The candidates for standardizing, classifying and coding are those fields that are likely to be heavily used in your record-linkage or querying, where being able to identify like with like values is important. Creators of databases built around the Source-oriented principle should exercise particular caution when employing these techniques.
