Part 1. Putting Data Driven Research In Perspective
1.4 What is Distant Reading?
What is Distant Reading?
In 2000, Franco Moretti coined the term “distant reading” to refer to the process of “understanding literature not by studying particular texts, but by aggregating and analyzing massive amounts of data.” The concept has been at the center of data conversations in the humanities. Whereas close reading relies on analysis about the apparent inner workings of a single literary text, distant reading takes account of hundreds and even thousands of compositions.
The idea of focusing on several works at a time is not a new concept. However, in a world where documents such as novels, speeches, song lyrics, poems, newspaper articles, movie and television scripts, and courtroom proceedings are increasingly available online to the public, distant reading has become popular and possible. Text-mining software can expand our ability to analyze a variety of patterns.
In this chapter, we will explain how the concept of distant reading applies to research, identify different functions of text mining software(s), and look at an example of a digital essay to see how topic modeling and text mining software can be applied to digital projects.
Keywords: Distant Reading, Text Mining, Voyant Tools, Topic Modeling,
Contextualizing Distant Reading
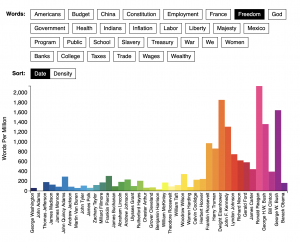
On January 18, 2015, The Atlantic published “The Language of the State of the Union” by Benjamin Schmidt and Mitch Fraa and graphics and production by Chris Barna, Libby Bawcombe, Noah Gordon, Betsy Ebersole, and Jennie Rothenberg Gritz. This interactive article tracks the presidential addresses’ to Congress ranging from George Washington to Barack Obama. Clicking on a list of 30 pre-selected words ranging from “American,” “Budget,” and “China,” to “Taxes,” “Trade,” and “Wages” reveals how they were used in chronological order. Some words remained consistent, some words fell out of use, and others grew in use over time.
For instance, the word “Indians” nearly fell out of all addresses after Teddy Roosevelt while the word “God” has been a part of every presidential speech since Franklin Roosevelt. Also, a word like “women” was a word rarely used in the president’s annual address. Franklin Roosevelt, Harry Truman, and John F. Kennedy used the word to address both men and women. However, Jimmie Carter and Ronald Regan began speaking directly to women about gendered issues. This visualization is an example of distant reading.
Distant reading basically means figuring out what a text document (or collection of texts) is about without having to read it in its entirety. This is the same text-processing and classification Google uses when we recall words or phrases online – such as looking for the recipes, instructions, song lyrics, movie reviews, and directions. Google has not read those webpages. Instead, the site uses a computer program that scans the documents for key words.
Like Google, we can use different digital tools to analyze documents of a text. We live in an age where information is over-abundant. Managing it effectively can mean the difference between finding what you are after and getting lost in a jumble of data. Distant reading is one process where we might use text mining software to analyze several textual documents.
Comparing and Contrasting Text Mining Tools
Text mining refers to the processes by which computers detect information from a large body of compositions. Data mining typically concentrates on all kinds of elements in datasets, whereas text mining usually concentrates on the content, such as the words in novels or speeches.
For my purposes, I primarily rely on two main software: Voyant Tools and Topic Modeling Tool. Both tools are good at analyzing large bodies of text in different ways.
Imagine that we wanted to analyze a dozen speeches by Martin Luther King, Jr. Voyant Tools would make it possible for us to instantly tabulate the number of words in the speeches as well as word types, processes known as distant reading. Voyant would allow us to identify specific words and build custom lists focusing on those words. The built-in visualization features on Voyant would empower us to perform a network analysis of the words in the speeches.
In another experiment, let us say we were interested in Martin Luther King’s speeches again, but this time, we want to focus on key themes in several of his speeches. We could then use a Topic Modeling Tool to perform a statistical analysis that scans a set of documents to detect linguistic patterns and then to cluster the words or “topics” together as groups.
Matt Daniels & Distant Reading

As a professor of African American literature and Digital Humanities, I am always on the lookout for projects that use computational methods in projects about Black verbal art. I have often returned to the Pudding for inspiration.
The Pudding has a mission to “explain ideas debated in culture with visual essays.” I have grown fond of the work of Matt Daniels, founder of the Pudding, over the last few years. His continued work producing hip hop visualizations shows me how I might incorporate DH concepts such as “distant reading” into my own projects.
In “The Largest Vocabulary In Hip Hop,” Matt Daniels performs a distant read by focusing on the first 35,000 lyrics of over 130 rappers. By hovering over a particular artist, it reveals their unique word usage. Another interactive feature of the chart is the drop-down menu that lets you select an individual artist. Throughout the digital essay, Daniels includes other charts comparing rappers by decade rap lyrics to words by artists in other genres.
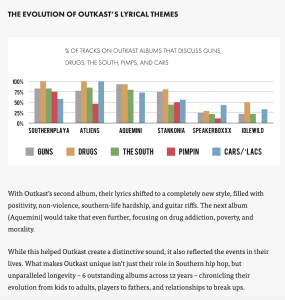
“Outkast, in Charts” is another essay that utilizes distant reading. Daniels uses text mining software similar to Topic Modeling Tool to assess the evolution of Outkast’s lyrical themes. He charts how the duo’s music coincided with an etymological change in hip hop vocabulary. He uses a bar graph to illustrate the shift in their album content. The chart makes it possible to consider complex patterns at a glance.
For a project like this, Topic Modeling Tool could be used to derive the various themes across albums. To discover the themes, a user could create a separate document of each of the duo’s albums, upload the corpus to Topic Modeling Tool, and interpret the string of words that the tool finds to be most prominent.
Daniel’s visualizations prompted me to think creatively about how distant reading can be applied to several different projects. Moreover, his projects show the variety of different text mining tools.
Key Takeaways – What is Distant Reading?
- Distant reading does not have a set methodology similar to close reading
- Distant reading allows scholars to measure sentence length, structure, and lexicon
- Distant reading gives a scholar patterns of data to analyze.
- Distant reading allows scholars to recognize patterns among several texts before focusing on a targeted group
By Kenton Rambsy
(See bibliography for sources)
Media Attributions
- Figure 1.4.1 – The Atlantic’s “The Language of the State of the Union” © Benjamin Schmidt, Mitch Fraa, Chris Barna, Libby Bawcombe, Noah Gordon, Betsy Ebersole, Jennie Rothenberg Gritz
- Private: Figure 1.4.2 – Largest Hip Hop Vocab © Matt Daniels
- Private: Figure 1.4.3 – Outkast, In Charts © Matt Daniels
Distant reading is an approach in literary studies that applies computational methods to literary data, usually derived from large digital libraries, for the purposes of literary history and theory. While the term is collective, and is used to refer to a range of different computational methods of analyzing literary data, similar approaches also include macroanalysis, cultural analytics, computational formalism, computational literary studies, quantitative literary studies, and algorithmic literary criticism.
Text mining, also referred to as text data mining, similar to text analytics, is the process of deriving high-quality information from text. It involves "the discovery by computer of new, previously unknown information, by automatically extracting information from different written resources."
Voyant Tools is an open-source, web-based application for performing text analysis. It supports scholarly reading and interpretation of texts or corpus, particularly by scholars in the digital humanities, but also by students and the general public. It can be used to analyze online texts or ones uploaded by users
Topic modeling is a machine learning technique that automatically analyzes text data to determine cluster words for a set of documents. This is known as 'unsupervised' machine learning because it doesn't require a predefined list of tags or training data that's been previously classified by humans.
