Part 2. The FLOAT Method
2.3 Locate
Locate a Data Source
When you are preparing for a data-driven project, you should take into account (1) if an available dataset has already been constructed related to your research topic, (2) how long it will take to create a custom dataset from scratch to fulfill your needs, and/or (3) how much labor and time will be needed to locate your data.
Our current moment constitutes an exciting and daunting time to look for and retrieve information. With so many search engines, publicly available datasets, and data scraping capabilities, our experiences locating useful data can be truly extraordinary and time-consuming. While the possibilities for locating items are wide open, it is necessary to place parameters on searches so that you are pursuing efficient searches. Ultimately, “locating data” can involve anything from downloading information from an online archive to having expert knowledge and being able to use specific technical skills to gather the data.
Tips for Locating Data
- Think about your deadline. Then, work backward thinking about how much time you would like to devote to collecting the information and the steps to process it such as transcribing texts, arranging digital materials, and coding information.
- It’s helpful to think about who might have collected the data you’re looking for such as governmental bodies, organizations, business/trade groups, or commercial entities and see what data they have available
Smart Data for the Humanities
Many humanists hear “data” and assume they do not have it. Many are surprised to learn that humanities data can take many forms, including images, music, poetry, short stories, and more. Even though there might not be a single dataset devoted to your research project, there are different ways to compile information together.
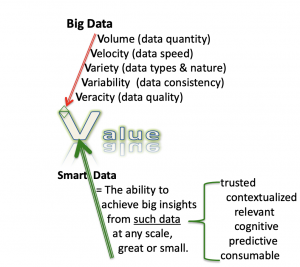
In “Smart Data for Digital Humanities” (February 18, 2017) Marci Lei Zeng provides a useful model for thinking about how we collect data pertinent to our research. Zeng defines “smart data” as “the way in which different data sources (including Big Data) are brought together, correlated, analyzed, etc., to be able to feed decision-making and action processes.”
“Smart data” is one method through which we might think about how to transform the unstructured data—such as heritage materials into not only machine-readable but also machine-processable resources—that are crucial to academic disciplines.
There are several different data collecting capabilities currently at our disposal. Researchers can locate data from already existing sources and databases. One important reason to look for compilations or sets of research data would be to cut down on the amount of labor in a given project. Using already compiled data, researchers can also extend previous studies over time, geography, or other parameters by combining multiple data sets and even locate individual facts or pieces of information that may be contained in a dataset.
For instance, in the class Dr. Kenton Rambsy teaches on the rapper, Jay-Z, students use the crowdsourced annotation site Genius to download Jay-Z lyrics to make a dataset about his word usage. Also, students scrape information about his music videos to compile information about his video directors from Wikipedia. Even though these datasets do not offer insight into every facet of Jay-Z’s career, this information is very helpful when answering focused research questions about particular topics. We should begin to think about the possibilities when we join disparate data sources together for specific research questions and projects. Ultimately, we must get creative about the ways in which we locate and create data sources.
To locate and/or construct a usable data source, we might consider:
- using Voyant Tools to transform texts into quantitative data.
- reading several documents using Topic Modeling Tool.
- using a simple formula to scrape data from Wikipedia using Google Sheets.
- using an API to get information from Twitter.
We can even develop much more sophisticated skills and using a coding language such as Python to collect a lot more information. Before coming up with custom datasets, think smarter and not harder.
Below, we have compiled a list of publicly available datasets. These datasets could be potentially edited or combined with already existing information to answer a range of research questions.
Accessible data
Data.gov – https://www.data.gov/
- Data.gov is the central clearinghouse for open data from the United States federal government and also provides access to many local government and non-federal open data resources.
Fatal Encounters – https://fatalencounters.org
- Hi, my name is D. Brian Burghart. I’m a lifelong, award-winning journalist. I’ve created this page because I believe in a democracy, citizens should be able to figure out how many people are killed during interactions with law enforcement, why they were killed, and whether training and policies can be modified to decrease the number of officer-involved deaths.
Kaggle Open Datasets – https://www.kaggle.com/datasets
- Kaggle allows users to find and publish data sets, explore and build models in a web-based data-science environment, work with other data scientists and machine learning engineers, and enter competitions to solve data science challenges
Mapping Police Violence – https://mappingpoliceviolence.org
- This information has been meticulously sourced from official police use of force data collection programs in states like California, Texas and Virginia, combined with nationwide data from the Fatal Encounters database, an impartial crowdsourced database on police killings. We’ve also done extensive original research to further improve the quality and completeness of the data; searching social media, obituaries, criminal records databases, police reports and other sources to identify the race of 90 percent of all victims in the database.
MIT Election Lab – https://electionlab.mit.edu/
- Our mission is to advance and disseminate scientific knowledge about the conduct of elections, primarily in the United States, but with attention to the rest of the world.
Open data site finder (Tableau Public viz) – https://public.tableau.com/profile/digitalteam#!/vizhome/OpenDataSiteFinder/OpenData
- This interactive list is used to locate and navigate open data sites around the world. The filters and map focus the contents of the table below. Table rows link to urls.
Pew Research Center – https://www.pewresearch.org/download-datasets/
- Pew Research Center is a nonpartisan fact tank that informs the public about the issues, attitudes and trends shaping the world. We conduct public opinion polling, demographic research, content analysis and other data-driven social science research.
Prison Policy Initiative – https://www.prisonpolicy.org/data/
- The non-profit, non-partisan Prison Policy Initiative produces cutting edge research to expose the broader harm of mass criminalization, and then sparks advocacy campaigns to create a more just society.
Replication Data for: Rule By Violence, Rule by Law: Lynching, Jim Crow, and the Continuing Evolution of Voter Suppression in the U.S. – https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/YFQE9W
- Although restricting formal voting rights—voter suppression—is not uncommon in democracies, its incidence and form vary widely. This collection of data illustrates our arguments by analyzing the transition from decentralized, violent voter suppression through the use of lynchings (and associated violence) to the centralized, less violent suppression of black voting in the post-Reconstruction South.
Texas Public Policy Foundation – https://www.texaspolicy.com/election-history-dataset/
- The Foundation’s mission is to promote and defend liberty, personal responsibility, and free enterprise in Texas and the nation by educating and affecting policymakers and the Texas public policy debate with academically sound research and outreach.
United States Election Project – http://www.electproject.org/
- The United States Elections Project is an information source for the United States electoral system. The mission of the project is to provide timely and accurate election statistics, electoral laws, research reports, and other useful information regarding the United States electoral system. By providing this information, the project seeks to inform the people of the United States on how their electoral system works, how it may be improved, and how they can participate in it.
World Bank Open Data – https://data.worldbank.org/
- At the World Bank, the Development Data Group coordinates statistical and data work and maintains a number of macro, financial and sector databases. Working closely with the Bank’s regions and Global Practices, the group is guided by professional standards in the collection, compilation and dissemination of data to ensure that all data users can have confidence in the quality and integrity of the data produced.
