10.3 Operational definitions
Learning Objectives
Learners will be able to…
- Define and give an example of indicators and attributes for a variable
- Apply the three components of an operational definition to a variable
- Distinguish between levels of measurement for a variable and how those differences relate to measurement
- Describe the purpose of composite measures like scales and indices
Conceptual definitions are like dictionary definitions. They tell you what a concept means by defining it using other concepts. Operationalization occurs after conceptualization and is the process by which researchers spell out precisely how a concept will be measured in their study. It involves identifying the specific research procedures we will use to gather data about our concepts. It entails identifying indicators that can identify when your variable is present or not, the magnitude of the variable, and so forth.

Indicators
Operationalization works by identifying specific indicators that will be taken to represent the ideas we are interested in studying. Let’s look at an example. Each day, Gallup researchers poll 1,000 randomly selected Americans to ask them about their well-being. To measure well-being, Gallup asks these people to respond to questions covering six broad areas: physical health, emotional health, work environment, life evaluation, healthy behaviors, and access to basic necessities. Gallup uses these six factors as indicators of the concept that they are really interested in, which is well-being.
Identifying indicators can be even simpler than this example. Political party affiliation is another relatively easy concept for which to identify indicators. If you asked a person what party they voted for in the last national election (or gained access to their voting records), you would get a good indication of their party affiliation. Of course, some voters split tickets between multiple parties when they vote and others swing from party to party each election, so our indicator is not perfect. Indeed, if our study were about political identity as a key concept, operationalizing it solely in terms of who they voted for in the previous election leaves out a lot of information about identity that is relevant to that concept. Nevertheless, it’s a pretty good indicator of political party affiliation.
Choosing indicators is not an arbitrary process. Your conceptual definitions point you in the direction of relevant indicators and then you can identify appropriate indicators in a scholarly manner using theory and empirical evidence. Specifically, empirical work will give you some examples of how the important concepts in an area have been measured in the past and what sorts of indicators have been used. Often, it makes sense to use the same indicators as previous researchers; however, you may find that some previous measures have potential weaknesses that your own study may improve upon.
So far in this section, all of the examples of indicators deal with questions you might ask a research participant on a questionnaire for survey research. If you plan to collect data from other sources, such as through direct observation or the analysis of available records, think practically about what the design of your study might look like and how you can collect data on various indicators feasibly. If your study asks about whether participants regularly change the oil in their car, you will likely not observe them directly doing so. Instead, you would rely on a survey question that asks them the frequency with which they change their oil or ask to see their car maintenance records.
Exercises
TRACK 1 (IF YOU ARE CREATING A RESEARCH PROPOSAL FOR THIS CLASS):
What indicators are commonly used to measure the variables in your research question?
- How can you feasibly collect data on these indicators?
- Are you planning to collect your own data using a questionnaire or interview? Or are you planning to analyze available data like client files or raw data shared from another researcher’s project?
Remember, you need raw data. Your research project cannot rely solely on the results reported by other researchers or the arguments you read in the literature. A literature review is only the first part of a research project, and your review of the literature should inform the indicators you end up choosing when you measure the variables in your research question.
TRACK 2 (IF YOU AREN’T CREATING A RESEARCH PROPOSAL FOR THIS CLASS):
You are interested in studying older adults’ social-emotional well-being. Specifically, you would like to research the impact on levels of older adult loneliness of an intervention that pairs older adults living in assisted living communities with university student volunteers for a weekly conversation.
What indicators are commonly used to measure the variables in your research question?
- How could you feasibly collect data on these indicators?
- Would you collect your own data using a questionnaire or interview? Or would you analyze available data like client files or raw data shared from another researcher’s project?
Steps in the Operationalization Process
Unlike conceptual definitions which contain other concepts, operational definition consists of the following components: (1) the variable being measured and its attributes, (2) the measure you will use, and (3) how you plan to interpret the data collected from that measure to draw conclusions about the variable you are measuring.
Step 1 of Operationalization: Specify variables and attributes
The first component, the variable, should be the easiest part. At this point in quantitative research, you should have a research question with identifiable variables. When social scientists measure concepts, they often use the language of variables and attributes. A variable refers to a quality or quantity that varies across people or situations. Attributes are the characteristics that make up a variable. For example, the variable hair color could contain attributes such as blonde, brown, black, red, gray, etc.
Levels of measurement
A variable’s attributes determine its level of measurement. There are four possible levels of measurement: nominal, ordinal, interval, and ratio. The first two levels of measurement are categorical, meaning their attributes are categories rather than numbers. The latter two levels of measurement are continuous, meaning their attributes are numbers within a range.
Nominal level of measurement
Hair color is an example of a nominal level of measurement. At the nominal level of measurement , attributes are categorical, and those categories cannot be mathematically ranked. In all nominal levels of measurement, there is no ranking order; the attributes are simply different. Gender and race are two additional variables measured at the nominal level. A variable that has only two possible attributes is called binary or dichotomous. If you are measuring whether an individual has received a specific service, this is a dichotomous variable, as the only two options are received or not received.
What attributes are contained in the variable hair color? Brown, black, blonde, and red are common colors, but if we only list these attributes, many people may not fit into those categories. This means that our attributes were not exhaustive. Exhaustiveness means that every participant can find a choice for their attribute in the response options. It is up to the researcher to include the most comprehensive attribute choices relevant to their research questions. We may have to list a lot of colors before we can meet the criteria of exhaustiveness. Clearly, there is a point at which exhaustiveness has been reasonably met. If a person insists that their hair color is light burnt sienna, it is not your responsibility to list that as an option. Rather, that person would reasonably be described as brown-haired. Perhaps listing a category for other color would suffice to make our list of colors exhaustive.
What about a person who has multiple hair colors at the same time, such as red and black? They would fall into multiple attributes. This violates the rule of mutual exclusivity, in which a person cannot fall into two different attributes. Instead of listing all of the possible combinations of colors, perhaps you might include a multi-color attribute to describe people with more than one hair color.

Making sure researchers provide mutually exclusive and exhaustive attribute options is about making sure all people are represented in the data record. For many years, the attributes for gender were only male or female. Now, our understanding of gender has evolved to encompass more attributes that better reflect the diversity in the world. Children of parents from different races were often classified as one race or another, even if they identified with both. The option for bi-racial or multi-racial on a survey not only more accurately reflects the racial diversity in the real world but also validates and acknowledges people who identify in that manner. If we did not measure race in this way, we would leave empty the data record for people who identify as biracial or multiracial, impairing our search for truth.
Ordinal level of measurement
Unlike nominal-level measures, attributes at the ordinal level of measurement can be rank-ordered. For example, someone’s degree of satisfaction in their romantic relationship can be ordered by magnitude of satisfaction. That is, you could say you are not at all satisfied, a little satisfied, moderately satisfied, or highly satisfied. Even though these have a rank order to them (not at all satisfied is certainly worse than highly satisfied), we cannot calculate a mathematical distance between those attributes. We can simply say that one attribute of an ordinal-level variable is more or less than another attribute. A variable that is commonly measured at the ordinal level of measurement in social work is education (e.g., less than high school education, high school education or equivalent, some college, associate’s degree, college degree, graduate degree or higher). Just as with nominal level of measurement, ordinal-level attributes should also be exhaustive and mutually exclusive.
Rating scales for ordinal-level measurement
The fact that we cannot specify exactly how far apart the responses for different individuals in ordinal level of measurement can become clear when using rating scales. If you have ever taken a customer satisfaction survey or completed a course evaluation for school, you are familiar with rating scales such as, “On a scale of 1-5, with 1 being the lowest and 5 being the highest, how likely are you to recommend our company to other people?” Rating scales use numbers, but only as a shorthand, to indicate what attribute (highly likely, somewhat likely, etc.) the person feels describes them best. You wouldn’t say you are “2” likely to recommend the company, but you would say you are “not very likely” to recommend the company. In rating scales the difference between 2 = “not very likely” and 3 = “somewhat likely” is not quantifiable as a difference of 1. Likewise, we couldn’t say that it is the same as the difference between 3 = “somewhat likely” and 4 = “very likely.”
Rating scales can be unipolar rating scales where only one dimension is tested, such as frequency (e.g., Never, Rarely, Sometimes, Often, Always) or strength of satisfaction (e.g., Not at all, Somewhat, Very). The attributes on a unipolar rating scale are different magnitudes of the same concept.
There are also bipolar rating scales where there is a dichotomous spectrum, such as liking or disliking (Like very much, Like somewhat, Like slightly, Neither like nor dislike, Dislike slightly, Dislike somewhat, Dislike very much). The attributes on the ends of a bipolar scale are opposites of one another. Figure 10.1 shows several examples of bipolar rating scales.

Interval level of measurement
Interval measures are continuous, meaning the meaning and interpretation of their attributes are numbers, rather than categories. Temperatures in Fahrenheit and Celsius are interval level, as are IQ scores and credit scores. Just like variables measured at the ordinal level, the attributes for variables measured at the interval level should be mutually exclusive and exhaustive, and are rank-ordered. In addition, they also have an equal distance between the attribute values.
The interval level of measurement allows us to examine “how much more” is one attribute when compared to another, which is not possible with nominal or ordinal measures. In other words, the unit of measurement allows us to compare the distance between attributes. The value of one unit of measurement (e.g., one degree Celsius, one IQ point) is always the same regardless of where in the range of values you look. The difference of 10 degrees between a temperature of 50 and 60 degrees Fahrenheit is the same as the difference between 60 and 70 degrees Fahrenheit.
We cannot, however, say with certainty what the ratio of one attribute is in comparison to another. For example, it would not make sense to say that a person with an IQ score of 140 has twice the IQ of a person with a score of 70. However, the difference between IQ scores of 80 and 100 is the same as the difference between IQ scores of 120 and 140.
You may find research in which ordinal-level variables are treated as if they are interval measures for analysis. This can be a problem because as we’ve noted, there is no way to know whether the difference between a 3 and a 4 on a rating scale is the same as the difference between a 2 and a 3. Those numbers are just placeholders for categories.
Ratio level of measurement
The final level of measurement is the ratio level of measurement. Variables measured at the ratio level of measurement are continuous variables, just like with interval scale. They, too, have equal intervals between each point. However, the ratio level of measurement has a true zero, which means that a value of zero on a ratio scale means that the variable you’re measuring is absent. For example, if you have no siblings, the a value of 0 indicates this (unlike a temperature of 0 which does not mean there is no temperature). What is the advantage of having a “true zero?” It allows you to calculate ratios. For example, if you have a three siblings, you can say that this is half the number of siblings as a person with six.
At the ratio level, the attribute values are mutually exclusive and exhaustive, can be rank-ordered, the distance between attributes is equal, and attributes have a true zero point. Thus, with these variables, we can say what the ratio of one attribute is in comparison to another. Examples of ratio-level variables include age and years of education. We know that a person who is 12 years old is twice as old as someone who is 6 years old. Height measured in meters and weight measured in kilograms are good examples. So are counts of discrete objects or events such as the number of siblings one has or the number of questions a student answers correctly on an exam. Measuring interval and ratio data is relatively easy, as people either select or input a number for their answer. If you ask a person how many eggs they purchased last week, they can simply tell you they purchased `a dozen eggs at the store, two at breakfast on Wednesday, or none at all.
The differences between each level of measurement are visualized in Table 10.2.
| Nominal | Ordinal | Interval | Ratio | |
| Exhaustive | X | X | X | X |
| Mutually exclusive | X | X | X | X |
| Rank-ordered | X | X | X | |
| Equal distance between attributes | X | X | ||
| True zero point | X |
Levels of measurement=levels of specificity
We have spent time learning how to determine a variable’s level of measurement. Now what? How could we use this information to help us as we measure concepts and develop measurement tools? First, the types of statistical tests that we are able to use depend on level of measurement. With nominal-level measurement, for example, the only available measure of central tendency is the mode. With ordinal-level measurement, the median or mode can be used. Interval- and ratio-level measurement are typically considered the most desirable because they permit any indicators of central tendency to be computed (i.e., mean, median, or mode). Also, ratio-level measurement is the only level that allows meaningful statements about ratios of scores. The higher the level of measurement, the more options we have for the statistical tests we are able to conduct. This knowledge may help us decide what kind of data we need to gather, and how.
That said, we have to balance this knowledge with the understanding that sometimes, collecting data at a higher level of measurement could negatively impact our studies. For instance, sometimes providing answers in ranges may make prospective participants feel more comfortable responding to sensitive items. Imagine that you were interested in collecting information on topics such as income, number of sexual partners, number of times someone used illicit drugs, etc. You would have to think about the sensitivity of these items and determine if it would make more sense to collect some data at a lower level of measurement (e.g., nominal: asking if they are sexually active or not) versus a higher level such as ratio (e.g., their total number of sexual partners).
Finally, sometimes when analyzing data, researchers find a need to change a variable’s level of measurement. For example, a few years ago, a student was interested in studying the association between mental health and life satisfaction. This student used a variety of measures. One item asked about the number of mental health symptoms, reported as the actual number. When analyzing data, the student examined the mental health symptom variable and noticed that she had two groups, those with none or one symptoms and those with many symptoms. Instead of using the ratio level data (actual number of mental health symptoms), she collapsed her cases into two categories, few and many. She decided to use this variable in her analyses. It is important to note that you can move a higher level of data to a lower level of data; however, you are unable to move a lower level to a higher level.
Exercises
TRACK 1 (IF YOU ARE CREATING A RESEARCH PROPOSAL FOR THIS CLASS):
- Check that the variables in your research question can vary…and that they are not constants or one of many potential attributes of a variable.
- Think about the attributes your variables have. Are they categorical or continuous? What level of measurement seems most appropriate?
TRACK 2 (IF YOU AREN’T CREATING A RESEARCH PROPOSAL FOR THIS CLASS):
You are interested in studying older adults’ social-emotional well-being. Specifically, you would like to research the impact on levels of older adult loneliness of an intervention that pairs older adults living in assisted living communities with university student volunteers for a weekly conversation.
- Check that the variables in your research question can vary…and that they are not constants or one of many potential attributes of a variable.
- Think about the attributes your variables have. Are they categorical or continuous? What level of measurement seems most appropriate?
Step 2 of Operationalization: Specify measures for each variable
Let’s pick a social work research question and walk through the process of operationalizing variables to see how specific we need to get. Suppose we hypothesize that residents of a psychiatric unit who are more depressed are less likely to be satisfied with care. Remember, this would be an inverse relationship—as levels of depression increase, satisfaction decreases. In this hypothesis, level of depression is the independent (or predictor) variable and satisfaction with care is the dependent (or outcome) variable.
How would you measure these key variables? What indicators would you look for? Some might say that levels of depression could be measured by observing a participant’s body language. They may also say that a depressed person will often express feelings of sadness or hopelessness. In addition, a satisfied person might be happy around service providers and often express gratitude. While these factors may indicate that the variables are present, they lack coherence. Unfortunately, what this “measure” is actually saying is that “I know depression and satisfaction when I see them.” In a research study, you need more precision for how you plan to measure your variables. Individual judgments are subjective, based on idiosyncratic experiences with depression and satisfaction. They couldn’t be replicated by another researcher. They also can’t be done consistently for a large group of people. Operationalization requires that you come up with a specific and rigorous measure for seeing who is depressed or satisfied.
Finding a good measure for your variable depends on the kind of variable it is. Variables that are directly observable might include things like taking someone’s blood pressure, marking attendance or participation in a group, and so forth. To measure an indirectly observable variable like age, you would probably put a question on a survey that asked, “How old are you?” Measuring a variable like income might first require some more conceptualization, though. Are you interested in this person’s individual income or the income of their family unit? This might matter if your participant does not work or is dependent on other family members for income. Do you count income from social welfare programs? Are you interested in their income per month or per year? Even though indirect observables are relatively easy to measure, the measures you use must be clear in what they are asking, and operationalization is all about figuring out the specifics about how to measure what you want to know. For more complicated variables such as constructs, you will need compound measures that use multiple indicators to measure a single variable.
How you plan to collect your data also influences how you will measure your variables. For social work researchers using secondary data like client records as a data source, you are limited by what information is in the data sources you can access. If a partnering organization uses a given measurement for a mental health outcome, that is the one you will use in your study. Similarly, if you plan to study how long a client was housed after an intervention using client visit records, you are limited by how their caseworker recorded their housing status in the chart. One of the benefits of collecting your own data is being able to select the measures you feel best exemplify your understanding of the topic.
Composite measures
Depending on your research design, your measure may be something you put on a survey or pre/post-test that you give to your participants. For a variable like age or income, one well-worded item may suffice. Unfortunately, most variables in the social world are not so simple. Depression and satisfaction are multidimensional concepts. Relying on a indicator that is a single item on a questionnaire like a question that asks “Yes or no, are you depressed?” does not encompass the complexity of constructs.
For more complex variables, researchers use scales and indices (sometimes called indexes) because they use multiple items to develop a composite (or total) score as a measure for a variable. As such, they are called composite measures. Composite measures provide a much greater understanding of concepts than a single item could.
It can be complex to delineate between multidimensional and unidimensional concepts. If satisfaction were a key variable in our study, we would need a theoretical framework and conceptual definition for it. Perhaps we come to view satisfaction has having two dimensions: a mental one and an emotional one. That means we would need to include indicators that measured both mental and emotional satisfaction as separate dimensions of satisfaction. However, if satisfaction is not a key variable in your theoretical framework, it may make sense to operationalize it as a unidimensional concept.
Although we won’t delve too deeply into the process of scale development, we will cover some important topics for you to understand how scales and indices developed by other researchers can be used in your project.
Need to make better sense of the following content:
Scales
Measuring abstract concepts in concrete terms remains one of the most difficult tasks in empirical social science research.
A scale, XXXXXXXXXXXX.
The scales we discuss in this section are a different from “rating scales” discussed in the previous section. A rating scale is used to capture the respondents’ reactions to a given item on a questionnaire. For example, an ordinally scaled item captures a value between “strongly disagree” to “strongly agree.” Attaching a rating scale to a statement or instrument is not scaling. Rather, scaling is the formal process of developing scale items, before rating scales can be attached to those items.
If creating your own scale sounds painful, don’t worry! For most constructs, you would likely be duplicating work that has already been done by other researchers. Specifically, this is a branch of science called psychometrics. You do not need to create a scale for depression because scales such as the Patient Health Questionnaire (PHQ-9)[1], the Center for Epidemiologic Studies Depression Scale (CES-D)[2], and Beck’s Depression Inventory[3] (BDI) have been developed and refined over dozens of years to measure variables like depression. Similarly, scales such as the Patient Satisfaction Questionnaire (PSQ-18) have been developed to measure satisfaction with medical care. As we will discuss in the next section, these scales have been shown to be reliable and valid. While you could create a new scale to measure depression or satisfaction, a study with rigor would pilot test and refine that new scale over time to make sure it measures the concept accurately and consistently before using it in other research. This high level of rigor is often unachievable in smaller research projects because of the cost and time involved in pilot testing and validating, so using existing scales is recommended.
Unfortunately, there is no good one-stop-shop for psychometric scales. The Mental Measurements Yearbook provides a list of measures for social science variables, though it is incomplete and may not contain the full documentation for instruments in its database. It is available as a searchable database by many university libraries.
Perhaps an even better option could be looking at the methods section of the articles in your literature review. The methods section of each article will detail how the researchers measured their variables, and often the results section is instructive for understanding more about measures. In a quantitative study, researchers may have used a scale to measure key variables and will provide a brief description of that scale, its names, and maybe a few example questions. If you need more information, look at the results section and tables discussing the scale to get a better idea of how the measure works.
Looking beyond the articles in your literature review, searching Google Scholar or other databases using queries like “depression scale” or “satisfaction scale” should also provide some relevant results. For example, searching for documentation for the Rosenberg Self-Esteem Scale, I found this report about useful measures for acceptance and commitment therapy which details measurements for mental health outcomes. If you find the name of the scale somewhere but cannot find the documentation (i.e., all items, response choices, and how to interpret the scale), a general web search with the name of the scale and “.pdf” may bring you to what you need. Or, to get professional help with finding information, ask a librarian!
Unfortunately, these approaches do not guarantee that you will be able to view the scale itself or get information on how it is interpreted. Many scales cost money to use and may require training to properly administer. You may also find scales that are related to your variable but would need to be slightly modified to match your study’s needs. You could adapt a scale to fit your study, however changing even small parts of a scale can influence its accuracy and consistency. Pilot testing is always recommended for adapted scales, and researchers seeking to draw valid conclusions and publish their results should take this additional step.
Types of scales
Likert Scales
Although Likert scale is a term colloquially used to refer to almost any rating scale (e.g., a 0-to-10 life satisfaction scale), it has a much more precise meaning. In the 1930s, researcher Rensis Likert (pronounced LICK-ert) created a new approach for measuring people’s attitudes (Likert, 1932).[4] It involves presenting people with several statements—including both favorable and unfavorable statements—about some person, group, or idea. Respondents then express their approval or disapproval with each statement on a 5-point rating scale: Strongly Approve, Approve, Undecided, Disapprove, Strongly Disapprove. Numbers are assigned to each response and then summed across all items to produce a score representing the attitude toward the person, group, or idea. For items that are phrased in an opposite direction (e.g., negatively worded statements instead of positively worded statements), reverse coding is used so that the numerical scoring of statements also runs in the opposite direction. The scores for the entire set of items are totaled for a score for the attitude of interest. This type of scale came to be called a Likert scale, as indicated in Table 10.3 below. Scales that use similar logic but do not have these exact characteristics are referred to as “Likert-type scales.”
| Strongly approve
(5) |
Approve
(4) |
Undecided
(3) |
Disapprove
(2) |
Strongly disapprove
(1) |
|
| I like research more now than when I started reading this book. | |||||
| This textbook is easy to use. | |||||
| I feel confident about how well I understand levels of measurement. | |||||
| This textbook is helping me plan my research proposal. |
Semantic Differential Scales
Semantic differential scales are composite scales in which respondents are asked to indicate their opinions or feelings toward a single statement using different pairs of adjectives framed as polar opposites. Whereas in a Likert scale, a participant is asked how much they approve or disapprove of a statement, in a semantic differential scale the participant is asked to indicate how they about a specific item using several pairs of opposites. This makes the semantic differential scale an excellent technique for measuring people’s feelings toward objects, events, or behaviors. Table 10.4 provides an example of a semantic differential scale that was created to assess participants’ feelings about this textbook.
| 1) How would you rate your opinions toward this textbook? | ||||||
| Very much | Somewhat | Neither | Somewhat | Very much | ||
| Boring | Exciting | |||||
| Useless | Useful | |||||
| Hard | Easy | |||||
| Irrelevant | Applicable | |||||
Guttman Scales
A specialized scale for measuring unidimensional concepts was designed by Louis Guttman. A Guttman scale (also called cumulative scale) uses a series of items arranged in increasing order of intensity (least intense to most intense) of the concept. This type of scale allows us to understand the intensity of beliefs or feelings. Each item in the Guttman scale below has a weight (this is not indicated on the tool) which varies with the intensity of that item, and the weighted combination of each response is used as an aggregate measure of an observation.
Table XX presents an example of a Guttman Scale. Notice how the items move from lower intensity to higher intensity. A researcher reviews the yes answers and creates a score for each participant.
Example Guttman Scale Items
- I often felt the material was not engaging Yes/No
- I was often thinking about other things in class Yes/No
- I was often working on other tasks during class Yes/No
- I will work to abolish research from the curriculum Yes/No
Indices
An index is a composite score derived from aggregating measures of multiple indicators. At its most basic, an index sums up indicators. A well-known example of an index is the consumer price index (CPI), which is computed every month by the Bureau of Labor Statistics of the U.S. Department of Labor. The CPI is a measure of how much consumers have to pay for goods and services (in general) and is divided into eight major categories (food and beverages, housing, apparel, transportation, healthcare, recreation, education and communication, and “other goods and services”), which are further subdivided into more than 200 smaller items. Each month, government employees call all over the country to get the current prices of more than 80,000 items. Using a complicated weighting scheme that takes into account the location and probability of purchase for each item, analysts then combine these prices into an overall index score using a series of formulas and rules.
Another example of an index is the Duncan Socioeconomic Index (SEI). This index is used to quantify a person’s socioeconomic status (SES) and is a combination of three concepts: income, education, and occupation. Income is measured in dollars, education in years or degrees achieved, and occupation is classified into categories or levels by status. These very different measures are combined to create an overall SES index score. However, SES index measurement has generated a lot of controversy and disagreement among researchers.
The process of creating an index is similar to that of a scale. First, conceptualize the index and its constituent components. Though this appears simple, there may be a lot of disagreement on what components (concepts/constructs) should be included or excluded from an index. For instance, in the SES index, isn’t income correlated with education and occupation? And if so, should we include one component only or all three components? Reviewing the literature, using theories, and/or interviewing experts or key stakeholders may help resolve this issue. Second, operationalize and measure each component. For instance, how will you categorize occupations, particularly since some occupations may have changed with time (e.g., there were no Web developers before the Internet)? As we will see in step three below, researchers must create a rule or formula for calculating the index score. Again, this process may involve a lot of subjectivity, so validating the index score using existing or new data is important.
Differences between scales and indices
Though indices and scales yield a single numerical score or value representing a concept of interest, they are different in many ways. First, indices often comprise components that are very different from each other (e.g., income, education, and occupation in the SES index) and are measured in different ways. Conversely, scales typically involve a set of similar items that use the same rating scale (such as a five-point Likert scale about customer satisfaction).
Second, indices often combine objectively measurable values such as prices or income, while scales are designed to assess subjective or judgmental constructs such as attitude, prejudice, or self-esteem. Some argue that the sophistication of the scaling methodology makes scales different from indexes, while others suggest that indexing methodology can be equally sophisticated. Nevertheless, indexes and scales are both essential tools in social science research.
Scales and indices seem like clean, convenient ways to measure different phenomena in social science, but just like with a lot of research, we have to be mindful of the assumptions and biases underneath. What if the developers of scale or an index were influenced by unconscious biases? Or what if it was validated using only White women as research participants? Is it going to be useful for other groups? It very well might be, but when using a scale or index on a group for whom it hasn’t been tested, it will be very important to evaluate the validity and reliability of the instrument, which we address in the rest of the chapter.
Finally, it’s important to note that while scales and indices are often made up of items measured at the nominal or ordinal level, the scores on the composite measurement are continuous variables.
Exercises
TRACK 1 (IF YOU ARE CREATING A RESEARCH PROPOSAL FOR THIS CLASS):
Looking back to your work from the previous section, are your variables unidimensional or multidimensional?
- Describe the specific measures you will use (actual questions and response options you will use with participants) for each variable in your research question.
- If you are using a measure developed by another researcher but do not have all of the questions, response options, and instructions needed to implement it, put it on your to-do list to get them.
TRACK 2 (IF YOU AREN’T CREATING A RESEARCH PROPOSAL FOR THIS CLASS):
You are interested in studying older adults’ social-emotional well-being. Specifically, you would like to research the impact on levels of older adult loneliness of an intervention that pairs older adults living in assisted living communities with university student volunteers for a weekly conversation.
Looking back to your work from the previous section, are your variables unidimensional or multidimensional?
- Describe at least one specific measure you would use (actual questions and response options you would use with participants) for the dependent variable in your research question.
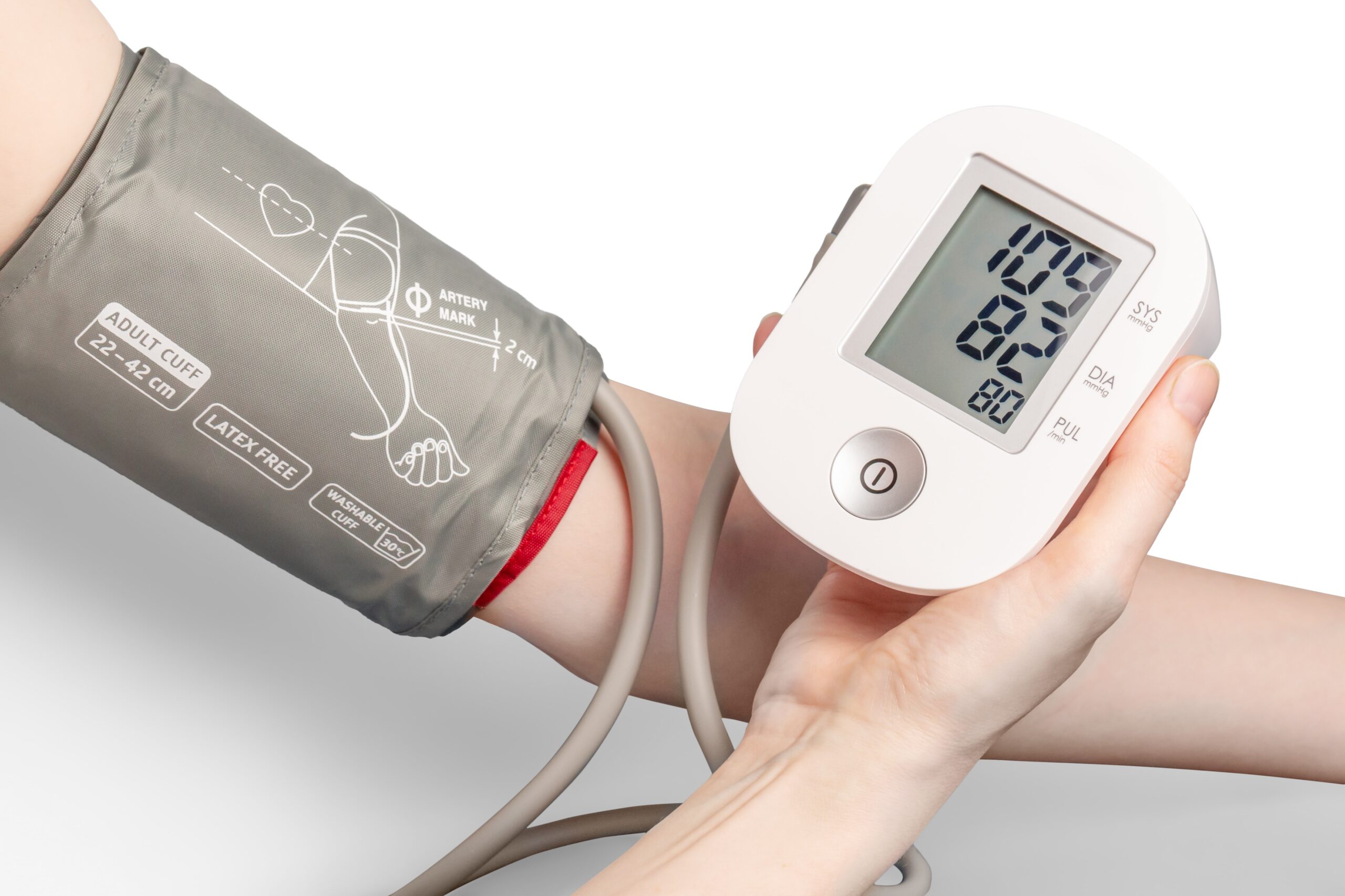
Step 3 in Operationalization: Determine how to interpret measures
The final stage of operationalization involves setting the rules for how the measure works and how the researcher should interpret the results. Sometimes, interpreting a measure can be incredibly easy. If you ask someone their age, you’ll probably interpret the results by noting the raw number (e.g., 22) someone provides and that it is lower or higher than other people’s ages. However, you could also recode that person into age categories (e.g., under 25, 20-29-years-old, generation Z, etc.). Even scales or indices may be simple to interpret. If there is an index of problem behaviors, one might simply add up the number of behaviors checked off–with a range from 1-5 indicating low risk of delinquent behavior, 6-10 indicating the student is moderate risk, etc. How you choose to interpret your measures should be guided by how they were designed, how you conceptualize your variables, the data sources you used, and your plan for analyzing your data statistically. Whatever measure you use, you need a set of rules for how to take any valid answer a respondent provides to your measure and interpret it in terms of the variable being measured.
For more complicated measures like scales, refer to the information provided by the author for how to interpret the scale. If you can’t find enough information from the scale’s creator, look at how the results of that scale are reported in the results section of research articles. For example, Beck’s Depression Inventory (BDI-II) uses 21 statements to measure depression and respondents rate their level of agreement on a scale of 0-3. The results for each question are added up, and the respondent is put into one of three categories: low levels of depression (1-16), moderate levels of depression (17-30), or severe levels of depression (31 and over) (NEEDS CITATION).
Operationalization is a tricky component of basic research methods, so don’t get frustrated if it takes a few drafts and a lot of feedback to get to a workable operational definition.
Key Takeaways
- Operationalization involves spelling out precisely how a concept will be measured.
- Operational definitions must include the variable, the measure, and how you plan to interpret the measure.
- There are four different levels of measurement: nominal, ordinal, interval, and ratio (in increasing order of specificity).
- Scales and indices are common ways to collect information and involve using multiple indicators in measurement.
- A key difference between a scale and an index is that a scale contains multiple indicators for one concept, whereas an indicator examines multiple concepts (components).
- Using scales developed and refined by other researchers can improve the rigor of a quantitative study.
Exercises
TRACK 1 (IF YOU ARE CREATING A RESEARCH PROPOSAL FOR THIS CLASS):
Use the research question that you developed in the previous chapters and find a related scale or index that researchers have used. If you have trouble finding the exact phenomenon you want to study, get as close as you can.
- What is the level of measurement for each item on each tool? Take a second and think about why the tool’s creator decided to include these levels of measurement. Identify any levels of measurement you would change and why.
- If these tools don’t exist for what you are interested in studying, why do you think that is?
TRACK 2 (IF YOU AREN’T CREATING A RESEARCH PROPOSAL FOR THIS CLASS):
You are interested in studying older adults’ social-emotional well-being. Specifically, you would like to research the impact on levels of older adult loneliness of an intervention that pairs older adults living in assisted living communities with university student volunteers for a weekly conversation.
Using your working research question, find a related scale or index that researchers have used to measure the dependent variable. If you have trouble finding the exact phenomenon you want to study, get as close as you can.
- What is the level of measurement for each item on the tool? Take a second and think about why the tool’s creator decided to include these levels of measurement. Identify any levels of measurement you would change and why.
- Kroenke, K., Spitzer, R. L., & Williams, J. B. (2001). The PHQ-9: validity of a brief depression severity measure. Journal of general internal medicine, 16(9), 606–613. https://doi.org/10.1046/j.1525-1497.2001.016009606.x ↵
- Radloff, L. S. (1977). The CES-D scale: A self report depression scale for research in the general population. Applied Psychological Measurements, 1, 385-401. ↵
- Beck, A. T., Ward, C. H., Mendelson, M., Mock, J., & Erbaugh, J. (1961). An inventory for measuring depression. Archives of general psychiatry, 4, 561–571. https://doi.org/10.1001/archpsyc.1961.01710120031004 ↵
- Likert, R. (1932). A technique for the measurement of attitudes. Archives of Psychology, 140, 1–55. ↵
process by which researchers spell out precisely how a concept will be measured in their study
Clues that demonstrate the presence, intensity, or other aspects of a concept in the real world
unprocessed data that researchers can analyze using quantitative and qualitative methods (e.g., responses to a survey or interview transcripts)
“a logical grouping of attributes that can be observed and measured and is expected to vary from person to person in a population” (Gillespie & Wagner, 2018, p. 9)
The characteristics that make up a variable
variables whose values are organized into mutually exclusive groups but whose numerical values cannot be used in mathematical operations.
variables whose values are mutually exclusive and can be used in mathematical operations
The lowest level of measurement; categories cannot be mathematically ranked, though they are exhaustive and mutually exclusive
Exhaustive categories are options for closed ended questions that allow for every possible response (no one should feel like they can't find the answer for them).
Mutually exclusive categories are options for closed ended questions that do not overlap, so people only fit into one category or another, not both.
Level of measurement that follows nominal level. Has mutually exclusive categories and a hierarchy (rank order), but we cannot calculate a mathematical distance between attributes.
An ordered set of responses that participants must choose from.
A rating scale where the magnitude of a single trait is being tested
A rating scale in which a respondent selects their alignment of choices between two opposite poles such as disagreement and agreement (e.g., strongly disagree, disagree, agree, strongly agree).
A level of measurement that is continuous, can be rank ordered, is exhaustive and mutually exclusive, and for which the distance between attributes is known to be equal. But for which there is no zero point.
The highest level of measurement. Denoted by mutually exclusive categories, a hierarchy (order), values can be added, subtracted, multiplied, and divided, and the presence of an absolute zero.
measurements of variables based on more than one one indicator
An empirical structure for measuring items or indicators of the multiple dimensions of a concept.
measuring people’s attitude toward something by assessing their level of agreement with several statements about it
Composite (multi-item) scales in which respondents are asked to indicate their opinions or feelings toward a single statement using different pairs of adjectives framed as polar opposites.
A composite scale using a series of items arranged in increasing order of intensity of the construct of interest, from least intense to most intense.
a composite score derived from aggregating measures of multiple concepts (called components) using a set of rules and formulas